Backend
(BE 개발자 5개월차) 연속 중복 제거 요구사항, 쿼리 대신 Read 전용 테이블을 선택한 이유 (ft. 현업에서 경험한 요구사항 풀어내기)
- -
👀 들어가기 전에
기존 내가 다운로드한 배경화면 목록에 대한 요구사항은 단순했다.
'사용자가 다운로드한 모든 배경화면을 빠짐없이 볼 수 있어야 한다'는 것이었다.
예를 들어, 사용자가 아래와 같은 순서로 배경화면을 다운로드했다고 가정해보자
1번 → 2번 → 3번 → 2번 → 2번 → 2번 → 5번 → 2번
이 경우, 가장 최근에 다운로드한 순서대로 목록이 노출되어 아래와 같은 형태로 보여야 했다.
2번 → 5번 → 2번 → 2번 → 2번 → 3번 → 2번 → 1번
즉, 다운로드 이력 전체를 시간 순으로 그대로 보여주는 방식이었다.
하지만 이후 새로운 기획 요구사항이 추가되었다.
같은 다운로드 이력이더라도 이번에는 단순한 시간 순 나열이 아니라 중복된 배경화면을 하나로 묶어 정리된 형태로 보여달라는 요구였다.
앞선 예시를 다시 적용하면, 결과는 다음과 같아야 한다.
2번 → 5번 → 2번 → 3번 → 2번 → 1번
중복된 2번 배경화면은 여러번 다운로드 되었더라도 연속된 중복은 제거되고 의미 있는 흐름만 남긴 구조로 보여야 하는 것이다.

이 글에서는 이러한 요구사항 변경을 마주하며 내가 어떤 고민을 했고 그 고민을 어떻게 설계와 구현으로 풀어냈는지에 대해 정리해보려 한다.
👀 본론
사건의 발단
사건의 발단은 이러했다. 원래 기획 의도대로라면 사용자가 동일한 배경화면을 연속으로 두 번 다운로드하더라도 그 요청은 그대로 처리되어야 했다. 이미 다운로드가 되어 있는 배경화면이더라도 사용자는 다시 한 번 다운로드하고 싶을 수 있고, 그 선택 자체를 제한할 이유는 없었기 때문이다. 이는 우리가 컴퓨터에서 사진을 다운로드할 때와도 같은 원리였다. 같은 파일을 두 번 다운로드한다고 해서 두 번째 다운로드가 막히지는 않는다.
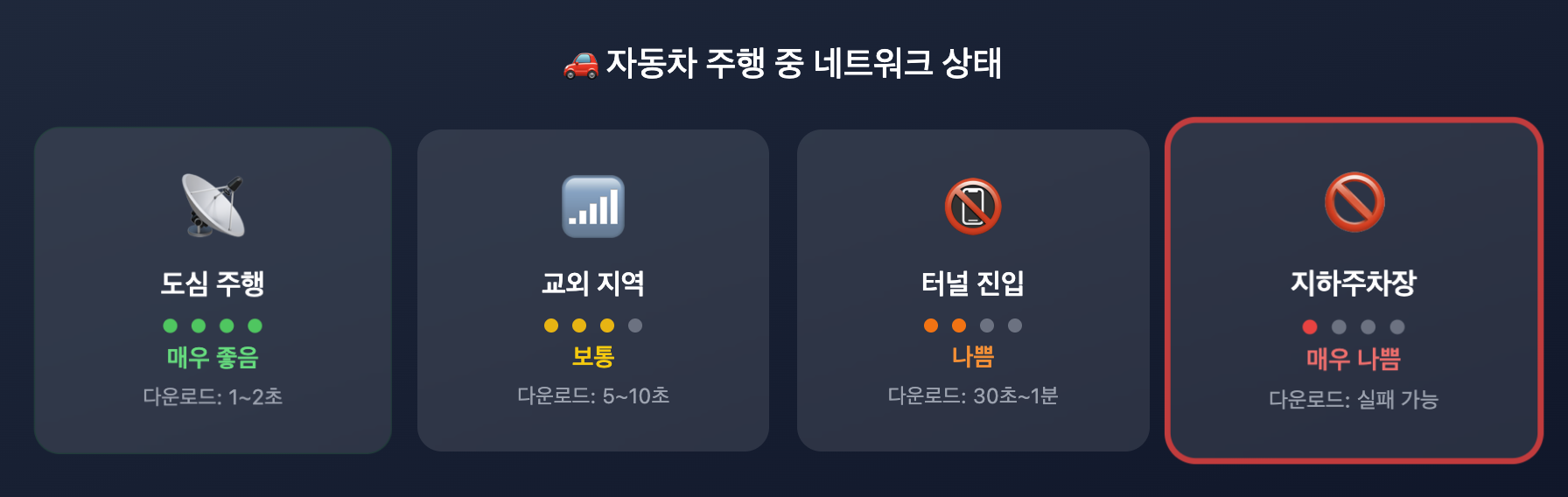
하지만 이 서비스는 자동차 웹앱이라는 특수한 환경 위에서 동작하고 있었다. 자동차 환경 특성상, 네트워크 상태가 항상 안정적일 수는 없었다. 문제는 바로 이 지점에서 발생했다. 사용자가 다운로드 버튼을 누르면 프론트엔드에서는 요청이 정상적으로 전달되었다고 판단해 곧바로 "다운로드 완료" 상태를 표시한다. 그러나 실제로는, 안드로이드 앱 단에서 배경화면을 내려받아 적용하는 과정이 네트워크 상태에 따라 상당한 시간이 걸릴 수 있었다. 현재 프론트엔드에서는 연속적으로 발생하는 중복 요청에 대해서는 일정 시간 간격을 두고 재요청을 막고 있었다. 하지만 문제는 연속적이지 않은 상황이었다.
예를 들면 이런 경우다.
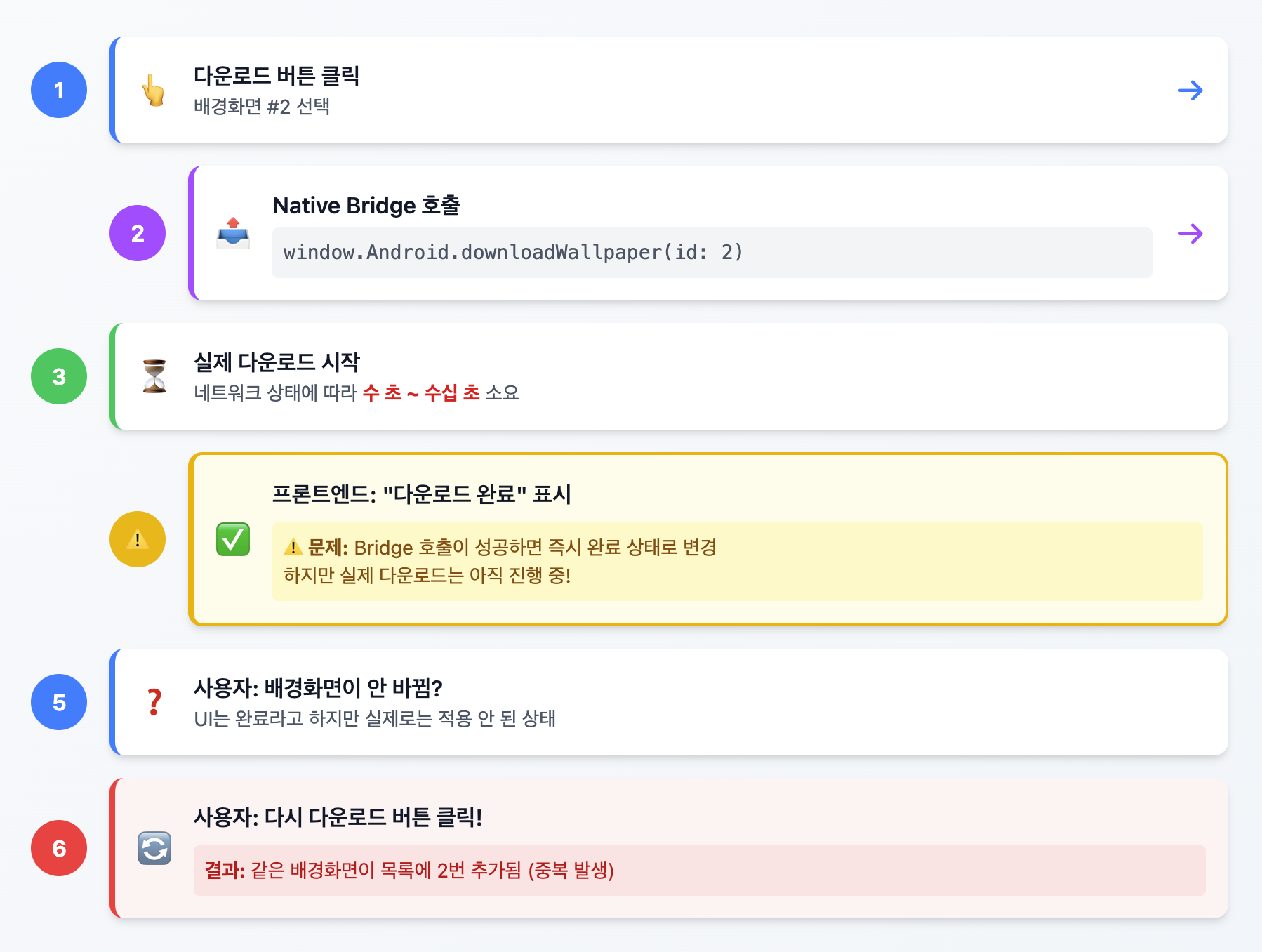
- 다운로드 버튼을 누른다
- 네트워크 상태가 매우 좋지 않아 실제 배경화면 적용은 아직 완료되지 않는다.
- 하지만 프론트엔드에서는 이미 "완료"상태를 보여준다.
- 사용자는 배경화면이 적용되지 않은 것을 보고 다시 앱에 진입한다.
- 그러고 다시 다운로드 버튼을 누른다.
- 이런 상황이 반복된다.
이 경우, 서비스 재요청에 대한 방지는 이미 되어 있는 상태였고, 논리적으로도 잘못된 요청이라고 보기 어렵다. 원래라면 정상적으로 처리되어야 할 흐름이었기 때문이다. 이에 기획적인 요구사항은 아래와 같았다.
다운로드한 배경화면 보기 화면에서는 연속된 배경화면이 그대로 노출되지 않도록 해주세요!
즉, 오늘 2번 배경화면을 다운로드하고 내일 다시 2번 배경화면을 다운로드하더라도 "다운로드한 배경화면 보기" 화면에서는 2번 배경화면이 연속해서 노출되어서는 안된다는 것이다. 다시 말해, 사용자가 동일한 배경화면을 다시 다운로드한 경우에는 다운로드 일자와 같은 메타 정보만 갱신하고, 목록 상에서는 이전 항목을 덮어쓰는 형태로 보여주길 원한 것이다.
🙋🏻♂️ 질문 1 : 통계적으로 해당 배경화면의 다운로드 횟수만 집계되면 되는건가요? 아니면 사용자별로도 따로 집계하실 예정인가요?
결국 서비스와 DB에서 우리가 고려하게 되는 점은 우리가 만든 서비스를 활용해서, 데이터를 활용해서, 통계적인 관점에서 사용자에게 어떤 유의미한 결과를 보여줄 것인가였다. 이를 위해서는 기획 단계에서부터 무엇을 어떤 기준으로 어디까지 집계할 것인지가 명확히 정의되어야 한다고 생각했다. 이 판단은 곧바로 DB 설계와도 직접적으로 연결되는 문제였다. (이 부분에 대해서는 뒤에서 자세히 이야기하려 한다.)
통계적으로 어떤 사용자들이 어떤 배경화면을 좋아하는지가 중요하기에
사용자에게 충분한 경험을 제공하기 위해 사용자별로 다운로드한 배경화면 데이터는
이전과 동일하게 유지되어야 한다.
예를 들어, 사용자가 아래와 같은 순서로 배경화면을 다운로드했다고 해보자.
1번 → 2번 → 3번 → 2번 → 2번 → 2번 → 5번 → 2번
회사의 입장에서는 (DB에서는) 아래와 같은 형태로 확인 가능해야 했다.
2번 → 5번 → 2번 → 2번 → 2번 → 3번 → 2번 → 1번
화면에 보여지는 방식과는 별개로, 데이터는 사용자의 실제 행동을 온전히 담고 있어야 했기 때문이다.
🙋🏻♂️ 질문 2 : 마이페이지를 들어갈 때마다 다운로드한 배경화면이 로딩 되나요?
다음으로 확인이 필요했던 것은 마이페이지 진입 시점에서 다운로드한 배경화면 목록을 언제 어떻게 로딩할 것인가였다.
여기에는 크게 두 가지 UX 패턴이 존재한다.
1. 별도의 진입 경로를 통해 확인하는 방식
예를 들어 아래 인스타그램을 보면, 마이페이지에 바로 저장된 게시물이 노출되지 않는다.

마이페이지 → 설정 및 활동 → 저장됨과 같은 경로를 통해서만 저장한 게시물들을 확인할 수 있다.
즉 클릭 이후에만 저장된 콘텐츠를 로딩하는 구조이다.
2. 마이페이지에서 즉시 노출하는 방식
반면 핀터레스트를 보면 마이페이지에 진입하는 순간 사용자가 저장한 컨텐츠들이 바로 노출된다.

추가적인 진입 없이 프로필 진입과 동시에 컨텐츠를 확인할 수 있는 구조다.
이 두 가지 방식 중, 우리 서비스에서는 어느 쪽을 선택할 것인지가 중요했다.
마이페이지 들어가면 바로 저장한 배경화면 확인이 가능해야 해요.
이는 곧, 마이페이지 진입 시마다 다운로드 이력을 조회해야 하고, 성능, 정렬 기준, 데이터 구조에 대한 고민이 뒤따른다는 의미이기도 했다.
이처럼 기획적인 요구사항들이 어느 정도 명확해지고 나자 비로소 '어떤 선택을 할 것인가'의 시간이 시작되었다.
이와 같은 고민이 필요했던 이유
이유는 하나였다. "어떻게 구현할 것인가"를 결정하려면, 그 전에 요구사항을 정확히 정의하는 과정이 반드시 필요했기 때문이다.
다시 처음으로 돌아가서 요구사항은 아래와 같다.
중복된 2번 배경화면은 여러번 다운로드 되었더라도
연속된 중복은 제거되고 의미 있는 흐름만 남긴 구조로 보여야 한다.
이 말을 듣자 마자 떠오른 구현 방법은 크게 두 가지였다.
- 쿼리로 조건을 걸어 '연속 중복 제거된 목록'을 바로 뽑는다.
- 별도의 테이블 (요약 / 뷰 테이블)을 설계해 화면용 데이터를 따로 관리한다.
그리고 1번에도 두가지 방법이 있다.
- 정적 쿼리로 규칙을 고정해 작성할 것인가
- 조건이 늘어날 것을 대비해 동적 쿼리로 확장 가능하게 작성할 것인가
우선, 쿼리로 해결하는 방향에서 연속 중복을 제거하는 조건을 어떻게 표현할 수 있을지 정리하고 왜 다른 방법을 선택했는지 한계가 무엇인지를 정리해보려 한다.
1) 정적 쿼리로 연속 중복 제거 하기
다운로드 이력을 최신순으로 정렬한 뒤, 각 row의 wallpaper_id가 바로 이전 row의 wallpaper_id와 같다면 그 row는 표출하지 않으면 된다. 즉, SQL로는 다음과 같은 조건이다.
SELECT w.*
FROM (
SELECT
dh.wallpaper_id,
dh.downloaded_at,
dh.id,
LAG(dh.wallpaper_id) OVER (
PARTITION BY dh.user_id
ORDER BY dh.downloaded_at DESC, dh.id DESC
) AS prev_wallpaper_id
FROM download_history dh
WHERE dh.user_id = ?
) t
JOIN wallpaper w ON w.id = t.wallpaper_id
WHERE t.prev_wallpaper_id IS NULL
OR t.wallpaper_id <> t.prev_wallpaper_id
ORDER BY t.downloaded_at DESC, t.id DESC;
실제 사용 쿼리는 아니고 예시 쿼리이다.
딱 보기에도 많이 복잡해진다. (실제로 이 글을 쓰기 위해서 짜는데 AI의 도움을 받아 짜게 되었다.)
2) 동적 쿼리로 연속 중복 제거하기
정적 쿼리로도 연속 중복 제거는 가능하다. 다만, 딱 보기에도 화면 요구사항이 조금만 늘어나도 쿼리는 더더욱 복잡해진다.
조건이 늘어나면 늘어날수록 위와 같은 정도 길이의 쿼리문을 여러개 짜야만 한다. 즉, 유지보수 비용이 기하급수적으로 증가한다.
그래서 다음으로 떠올린 방법은 동적 쿼리(Query DSL)로 확장 가능하게 구현하는 방식이었다.
하지만, 여기서 바로 문제가 생긴다.
연속 중복 제거는 WHERE 조건으로 해결되는 문제가 아니다. (위 쿼리를 짜면서 다시금 느꼈다.)
동적 쿼리는 조건이 늘어날수록 편한 것은 맞으나, 연속 중복을 제거하려면 단순 필터링이 아니라 순서 기반으로 비교가 되어야하는 문제이기에 ORM 수준에서 추상화하여 코드가 작성되기 어려웠다.
(물론, 먼저 데이터들을 가져오고 어플리케이션단에서 연속 중복이 제거되어도 되지만, 이 내용은 생략하겠다.)
그래서 어떻게 했나요?
결론부터 이야기하면, 별도의 테이블 (요약 / 뷰 테이블)을 설계해 화면용 데이터를 따로 관리하는 방법을 선택하였다.
이유는 앞선 질문들에서 찾을 수 있다.
다시 앞선 질문에 대한 답변들을 살펴보자.
데이터는 사용자별로도 따로 집계가 되어야한다. 즉, 다운로드한 배경화면 테이블에서 사용자 데이터와 엮어서 가져와야만 했다.
또한, 마이페이지 진입시 마이페이지에서 다운로드한 배경화면을 즉시 노출해야한다.
쿼리문으로 빼올 시, 위에서 작성한 쿼리를 사용할 수 밖에 없다.
이때, 발생하는 문제는 아래와 같다.
1) CPU 부하 (마이페이지 진입 = 매번 전체 로그 스캔)
위 쿼리가 드문드문 실행되는 쿼리면 사실 쿼리로 풀어내도 상관은 없다.
허나, 마이페이지 진입을 하면 매번 위 쿼리가 실행되어야한다.
한 사용자당 하루 n번을 사용한다고 할 때, active user가 늘어날수록 DB는 계속 "사용자 로그 + 정렬 + 윈도우"를 반복해서 수행한다.
정렬하고, 정렬된 결과를 한 줄씩 훑으면서 LAG()로 이전 row와 값을 비교하며 조건에 맞는 row만 남긴다.
이 작업들을 하는 동안 계속해서 CPU 계산 작업이 진행되게 되는 것이다. 즉, CPU의 부하가 늘어난다.
2) Buffer Pool의 효율 저하
DB가 디스크에서 읽은 데이터 페이지를 메모리에 캐싱하는 공간이 Buffer Pool이다.
이때, 로그 테이블은 결국 시간이 지날수록 계속 커지게 된다. 정렬 + 윈도우 계산은 넓은 범위까지 한 번에 읽게 된다. 최근 20개가 필요해서 페이징을 받더라도, 내부적으로는 그보다 훨씬 많은 row를 읽게 된다. (사실상 페이징 처리의 이점이 사라진다.) 버퍼 풀 Hit Ratio가 떨어지고 디스크 I/O가 증가하게 되며 전체 DB 성능이 나빠지게 된다.
3) 커넥션 점유 시간이 증가한다.
마이페이지 진입을 할 때마다, 이 쿼리가 실행되면, 정렬하고 윈도우를 하는 CPU를 잡아먹는 작업동안 커넥션이 반환되지 않는다.
결국 동시에 요청이 여러 개 들어오면, 커넥션 풀에서 사용중인 커넥션 수↑, 대기 중인 요청 수↑ 하게 되며 응답이 지연되고 타임아웃이 나게 될 수 있다.
결국 위 쿼리문을 실행하면 사용자 로그 전체를 대상으로 정렬과 window function을 반복 수행하면서 CPU 연산량이 누적되고, 대용량의 로그 페이지가 버퍼풀을 오염시키며 쿼리 실행 시간이 길어져 DB 커넥션이 장시간 점유되고 이로 인해 타임아웃 에러가 발생할 수 있다.
별도의 테이블을 따로 구성하자
이에 별도의 테이블 (요약 / 뷰 테이블)을 설계해 화면용 데이터를 따로 관리하도록 하였다.
화면용 테이블을 설계하면서 가장 먼저 고민했던 부분은 어떤 방식으로 Read 전용 테이블을 구축할 것인가이다.
비용을 들여 테이블을 늘리는 만큼 해당 비용 이상의 효과를 뽑을 수 있도록 깔끔하게 설계가 되어야한다고 판단했다.
우선 필요할 것 같은 값들을 정리해보았다.
- 기본 구별 ID값 (자동으로 붙는 PK ID 혹은 UUID, ULID 등 구분 되는 값)
- 사용자 ID (사용자 개개인을 구분할 수 있는 ID값)
- 배경화면 ID (배경화면을 구분할 수 있는 ID값)
- 시작 시간 (연속된 배경화면이 시작된 시간)
- 끝 시간 (연속된 배경화면 다운로드가 끝난 시간)
→ 시작 시간과 끝 시간의 경우 통계를 뽑는 과정에서 필요할 것이라 따로 추가 판단하였다. - 연속으로 눌린 횟수 (2 → 2 → 2 이면 횟수는 3)
→ 화면에서 몇번 눌렸는지에 대한 표시가 필요했기에 추가하였다.
(사용자가 몇번 다운로드했는지 왜 사용자 화면에서 다운로드하기를 여러번 눌렀는데도 한 번만 보이는지에 대한 설명이 필요하다고 생각했다.) - 가장 마지막 다운로드 이력 ID (다운로드한 배경화면에서 어떤 ID를 마지막으로 사용한 것인가)
→ 원본 로그의 ID가 필요하다고 판단했다.
위에 짧게 나마 어떤 사고과정을 거쳐 해당 테이블에 해당 칼럼들이 추가되었는지 작성하였으나 이제 더 자세히 풀어보려 한다.
읽기 전용 테이블에 필요한 칼럼은 어떤 것들이 있을까?
처음에는 읽기 전용 테이블이니만큼 최대한 단순하게 가져가는 것이 맞다고 생각했다.
그래서 초기 구상은 아래 정도였다.
- 기본 식별자 ID
- 사용자 ID
- 배경화면 ID
- 연속 다운로드 구간의 시작 시간
- 연속 다운로드 구간의 종료 시간
"이정도면 어떤 사용자가 어떤 배경화면을 언제부터 언제까지 연속으로 다운로드했는지"라는 화면 요구사항은 충분히 만족한다고 판단했기 떄문이었다. 읽기 전용 테이블이고, 통계의 기준 데이터는 어차피 Download History 테이블이 따로 존재했기 때문에 요약 테이블은 화면에 필요한 최소의 정보만 담는 것이 옳다고 생각했다.
하지만, 설계를 조금 더 깊이 들여다보면서 이 구조가 지금 당장 화면을 그리는데는 충분하지만 운영과 확장에는 취약할 수 있다는 점이 보이기 시작했다. 특히 아래 두 가지 질문에서 막히게 되었다.
이 구간이 정말 어디까지의 History를 반영한 상태인가?
연속 다운로드 구간을 읽기 전용 테이블로 관리한다는 것은 결국 원본을 담고 있는 History 테이블과 요약 데이터 사이에 시간차가 생길 수 있다는 의미다.
- 처리 지연
- 재시도
- 장애 복구 등...
아래와 같은 상황을 가정해보자.
다운로드 History 테이블은 아래와 같다.
| id | user_id | wallpaper_id | downloaded_at |
| 101 | A | 2 | 10:00:01 |
| 102 | A | 2 | 10:00:03 |
| 103 | A | 2 | 10:00:05 |
| 104 | A | 2 | 10:00:10 |
사용자 A는 10:00:01 ~ 10:00:06 사이에 배경화면 2를 연속으로 4번 다운로드했다.
이에 Read 전용 테이블에는 아래와 같은 segment가(하나의 읽기용 다운로드 기록을 편의상 Segment라 하자) 생성된다.
| segment_id | user_id | wallpaper_id | download_started_at | download_ended_at |
| 1 | A | 2 | 10:00:01 | 10:00:05 |
이때, 아래와 같은 문제가 발생해버린다.
- History id = 102,103 처리는 완료됨.
- id= 101 history 처리 직후 DB 장애 발생
- 트랜잭션은 커밋되었고 로그는 존재함
- 하지만 read 테이블 갱신 로직 실패
운영자가 장애 복구 후 read 테이블을 다시 갱신하려고 한다.
이 Segment는 다운로드 History 기준으로 어디까지 반영된 상태였지?
Read 테이블에는 이렇게만 남아있다.
| segment_id | user_id | wallpaper_id | download_started_at | download_ended_at |
| 1 | A | 2 | 10:00:01 | 10:00:05 |
하지만 이 정보만으로는 알 수 있는게 없다.
downloaded_at = 10:00:05인 history (id=103)까지는 반영된 것인가?
History 테이블 기준 id=102인 배경화면 까지만 반영된 것은 아닌가?
(다운로드 시작이 10:00:03 끝난 시간이 10:00:05일 수도 있는 것이다.)
다운로드가 끝난 시간은 결과적으로 나와있는 결론인 것인지, 어디까지 처리가 된 상태인지를 보장해주는 기준이 될 수 없다.
어떻게 해결할 수 있을 것인가?
last_history_id를 만든다. 어디까지 실행되었고, 어디서부터 다시 재처리 되어야 할지를 생각할 수 있도록 만들어주는 것이다.
아래 처럼 Read 전용 테이블을 만들었다고 하자.
| segment_id | user_id | wallpaper_id | started_at | ended_at | last_history_id |
| 1 | A | 2 | 10:00:01 | 10:00:05 | 103 |
이제 의미는 명확해졌다.
이 segment는 다운로드 History ID 기준 103번까지는 확실히 반영한 상태이다.
추후 복구할 때, download_history.id > last_history_id 기준으로 복구 처리 시작을 하면 된다.
트랜잭션은 어떻게 설계할 것인가?
이제 테이블 설계가 마무리 되어 트랜잭션 설계에 대한 고민이 시작되었다.
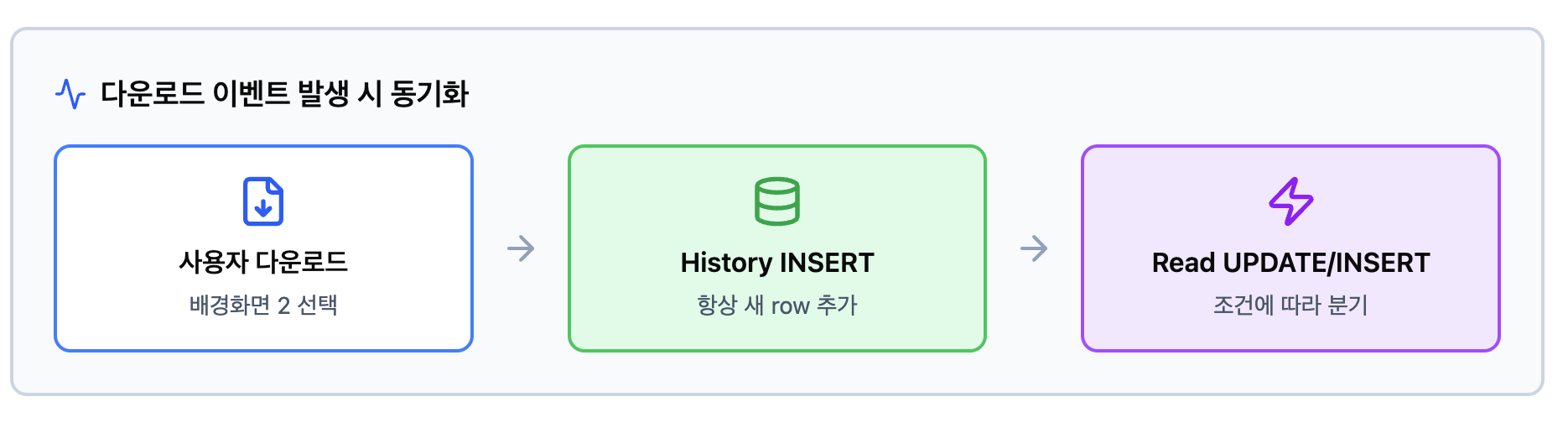
이제는 다운로드가 발생했을 때, 어떤 정보를 어떤 순서로 어떤 테이블에 기록할 것인가를 결정해야만 했다.
특히 이 서비스에서는 다운로드 이벤트가 발생할 때마다, History테이블과 Read 전용 테이블을 일관되게 갱신해야 했다.
이를 고민하다보면 아래와 같은 원칙이 정립된다.
- 원본 History는 반드시 남아야 한다.
다운로드한 History는 통계를 통한 서비스 제공의 기준 데이터이므로 어떤 경우에도 손실되거나 왜곡되어서는 안 된다. - 화면용 Read 테이블은 연속 중복이 제거된 상태를 유지해야 한다.
동일한 배경화면이 연속으로 눌리면 같은 row를 업데이트하고, 다른 배경화면이면 새로운 row를 생성해야 한다. - 두 작업은 모두 하나의 원자적 단위로 처리되어야 한다.
다운로드 요청 1번에 대해 History insert와 Read 테이블 update/insert는 항상 같은 트랜잭션 안에서 성공하거나 실패해야 한다.
(물론 문제가 생길 경우 대처하기 위해 위 DB 설계시 방어적 설계를 하였지만, 코딩은 항상 방어적이어야 한다고 생각한다.)
이 세가지를 동시에 만족하지 못하면 사용자 화면과 실제 데이터 상태가 어긋나는 문제가 발생하게 된다.
서비스 로직의 기본 형태
이 원칙을 코드로 풀어내게 되면 서비스 레이어의 트랜잭션은 다음과 같은 형태로 정리된다.
(아래 코드는 사내 보안으로 인해 새로 작성한 예시 코드이다.)
@Transactional
public void download(Long userId, Long wallpaperId) {
LocalDateTime now = LocalDateTime.now();
//원본 History는 항상 insert되어야 한다.
DownloadedWallpapers history = downloadedWallpapersRepo.save(
DownloadedWallpapers.create(userId, wallpaperId, now)
);
// 마지막 Read 테이블의 row 기준으로 처리를 나눠서 진행해야 한다.
DownloadWallpaperRead last = downloadReadRepo
.findTopByUserIdOrderByDownloadReadIdDesc(userId)
.orElse(null);
if (last != null && last.isSameWallpaper(wallpaperId)) {
//연속적으로 다운로드가 눌린 경우 기존 row를 업데이트한다.
last.touch(now, history.getId());
} else {
// 연속이 끊긴 경우 (즉 언제든 이전 배경화면이 지금 누른 배경화면과 동일하지 않은 경우) 새로운 row 생성
downloadReadRepo.save(DownloadWallpaperSegment.start(userId, wallpaperId, now, history.getId()));
}
}
이 구조는 앞에서 말했던 요구사항을 모두 충족하게 된다.
History는 항상 append되며, Read 테이블은 마지막으로 다운로드된 배경화면을 기준으로 갱신된다.
즉, 요청했던대로 history는 그대로 쌓고 화면은 요약한 상태만 유지하게 된다.
그리고 마주한 문제 : 동시성
코드를 작성하고 끝난 것이 아니다.
동일한 userId에 대해 다운로드 요청이 거의 동시에 들어오는 경우, 마지막 Read row를 기준으로 분기하는 이 로직은 race condition에 있어 취약했다.
예를 들어 아래와 같은 상황이 온다고 가정해보자.
두 요청이 동시에 last를 조회한다.
둘 다 같은 분기 조건을 만족한다.
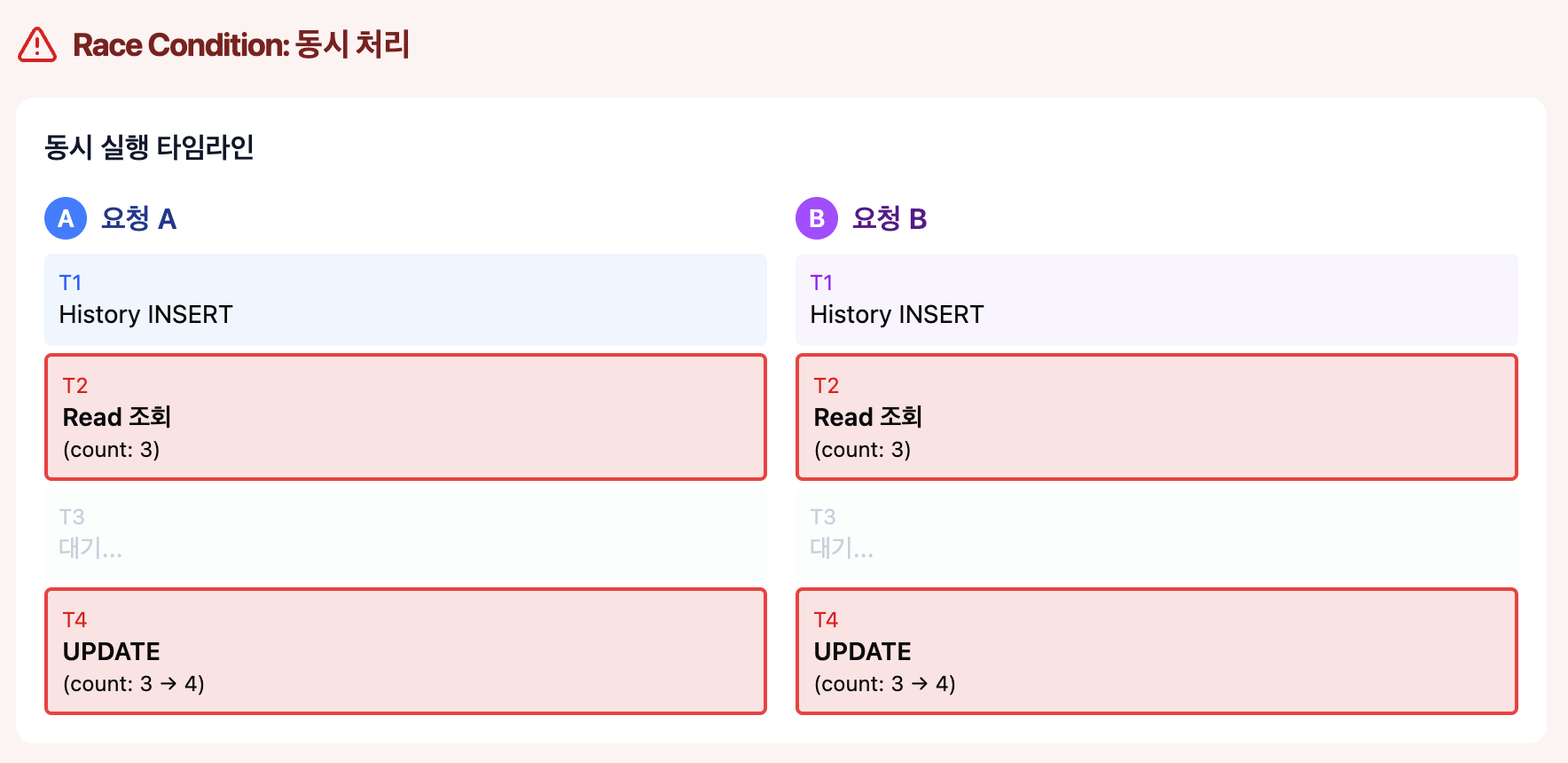
어떤 문제가 발생할까?
Read row가 중복되어 생성되거나 count나 lastHistoryId가 꼬일 수 있다.
아래 그림에서 예시를 살펴보자.

결국 아래와 같은 문제점이 발생하게 되는 것이다.

이를 방지하기 위해 결국 Read 테이블의 마지막 row를 조회하는 시점에서 쓰기 비관락을 걸어 user 단위로 처리 흐름을 직렬화했다.
또한, Read row가 아직 존재하지 않는 최초 다운로드 케이스에서는 별도의 user row락을 사용해 Read row가 중복 생성될 수 있는 상황까지 차단했다. 아래에서 더 자세하게 설명하겠다.
🔎 더 자세하게!
여기서 사용한 비관락은 MySQL (InnoDB)의 SELECT..FOR UPDATE를 이용한 row-level pessimistic lock이다.

마지막 Read row가 존재하는 경우에는 해당 row에 쓰기 락을 걸어 user 단위로 분기 로직을 직렬화했고,

Read row가 아직 존재하지 않는 최초 케이스에서는 user 기준 row를 FOR UPDATE로 잠가 InnoDB의 next-key lock이 적용되도록 하여 Read row의 중복 생성 가능성까지 차단한 것이다.
👀 마치며..
요구사항을 분석하고 해결해 나가는 과정은 단순히 기능 하나를 구현하는 작업이 아니라 문제를 정의하고, 질문을 통해 요구사항을 정제한 뒤 그 결과를 기술적인 설계로 풀어내는 전반적인 과정이었다.
요구사항을 처음 들었을 때는 "연속 중복을 제거해서 보여주면 된다"는 다소 단순한 문제처럼 보였다. 하지만 기획을 더 명확히 하기 위해 질문을 던지고, 그 질문에 대한 답을 하나씩 정리해 나가면서 이 문제가 UX, 통계 기준, 성능, 동시성까지 연결된 문제라는 점을 인지하게 되었다. 여러 조건을 동시에 만족시키기 위해 데이터 구조와 트랜잭션 경계를 다시 정의하는 과정을 거치며 기술적으로 가능한 여러 선택지를 열어두고 고민했다. 그 과정에서 사용자 경험을 최대한 개선할 수 있는 선택을 하려 노력했다.
이번 경험을 통해 요구사항을 그대로 코드로 옮기는 것보다 이 요구사항이 왜 나왔는지를 먼저 이해하고 그에 맞는 구조를 선택하는 것이 얼마나 중요한지를 다시 한 번 체감할 수 있었다. 결국 좋은 코딩이란 복잡한 로직을 잘 짜는 것보다 사용자의 경험을 기준으로 어떻게 더 나은 서비스를 제공할 수 있을지를 고민하는 데서 시작된다는 생각이 들었다.
'Backend' 카테고리의 다른 글
| (BE 개발자 5개월차) 첫 오픈소스 기여 : Json Schema와 마이그레이션 그 마지막 이야기 (feat. PR Merge) (0) | 2026.02.19 |
|---|---|
| (BE 개발자 5개월차 독후감) [Unit Testing : 단위 테스트] 독후감 마무리 (feat. 가치 있는 테스트 작성하기) (0) | 2026.02.07 |
| (BE 개발자 4개월차 독후감) Unit Testing : 단위 테스트 1차 독후감 (0) | 2026.01.24 |
| (BE 개발자 4개월차) 첫 오픈소스 기여 : Json Schema와 마이그레이션 (1) | 2026.01.14 |
| (BE 개발자 4개월차) 현업에서 고민한 DB I/O 줄이기 (0) | 2026.01.08 |
Contents
소중한 공감 감사합니다