Study
(CS Study) 스레드, 어디까지 알고 계십니까?
- -
👀 들어가기 전에
구름에서 진행한 프로펙트 부트캠프가 종료되고 CS Study를 진행해오면서 사용했던 발표 자료들을 기반으로 배웠던 내용을 다시 한 번 정리해 나가려 합니다. 지금까지 발표했던 내용들을 정리하고, 진행되는 내용들을 추가로 작성해나가며 채워보도록 하겠습니다.
이외에도 진행하는 다른 스터디들과 관련된 내용들도 함께 작성될 예정이니 많관부~!
👀 본론
들어가기전 퀴즈
- 멀티 스레드 환경에서 스레드를 많이 쓸수록 항상 어플리케이션의 성능이 좋아질까요?
- 어플리케이션을 수행하는 관점에서는 어떨까요?
- Context Switching 관점에서는 어떨까요? (CPU 코어가 고정이라는 전제를 합니다.)
- CPU Bound 와 I/O Bound의 관점에서는 어떨까요? - 프로젝트를 진행하며 비동기처리를 진행하신 분들이 많이 계실텐데, @Async 어노테이션을 통한 비동기처리를 하셨을텐데, 그 때 thread-pool 설정을 하셨나요?
- 하셨다면 어떻게 하셨나요? 만약 thread-pool 설정이 없었다면 어떻게 동작했을까요?
- 왜 설정을 안하면 문제가 생길까요?
- private 메소드에서는 비동기로 해당 메소드가 작동할 수 있을까요?
혹시 위 질문들에 답변을 다 하셨나요? 제가 공부를 하게 되면서 저도 새롭게 알아갔던 내용들이 대부분들이 많아 이에 대해 설명해보도록 하겠습니다.
Thread, 왜 알아야할까요?
컴퓨터 관련 전공을 하신 분들이라면 당연히 컴퓨터구조를 배우며 Thread를 한 번쯤은 배우게 되며 꼭 한 번쯤은 교수님들께서 강조를 하시게 되는 부분입니다. 왜 그럴까요? 제가 전공생일 당시부터 이 공부를 시작하기까지 항상 왜 해야하는지를 몰랐으며 의문을 달고 있었습니다. 우선, 이를 이해하기 위해서는 근본적으로 컴퓨터가 탄생한 배경부터 시작하도록 하겠습니다.
옛날로 돌아가서...

위 컴퓨터는 1970년대 후반 ~ 1980년대에 초반의 컴퓨터들입니다.
이 컴퓨터들은 단일 프로세스로 동작하는 컴퓨터들입니다.
단일 프로세스에는 어떤 문제들이 있었을까요?

우선 옆의 사진은 프로세스를 메모리의 관점에서 이해해보기 위한 사진입니다. Stack영역은 지역변수가 할당될 때, 함수가 호출될 때 점점 쌓이는 구간이며 Heap은 메모리 Allocation을 할 때마다 점점 추가됩니다. 이때, 스택도 증가하고 힙도 증가하게 되면 언젠가는 만나게 될 것입니다.
하지만, 만나면 안되겠죠?
그렇기 때문에 시간이 흐르고, 기술이 발전함에 따라 단일 프로세스에서는 메모리의 한계가 보이게 됩니다. 그렇다면 이 부분을 어떻게 해결할 수 있을까요?
프로세스간 통신을 시키자!

프로세스가 하나 더 있고 프로세스끼리 통신을 한다면 가능할 것 같습니다.
통신을 시킨다면 여러가지 방법이 있을 것 같습니다.
메모리 자체를 공유하는 방법이 있을 수 있을 것 같고, 반대로 Message queue를 통해 Message를 Passing하여도 될 것 같습니다.
공유 메모리
공유 메모리란 '두 프로세스가 같은 메모리를 공유한다면 어떨까?' 하는 생각에서 출발한 아이디어입니다.
그런데 이 방식에는 몇가지 문제점이 있습니다.
동시에 쓰거나 읽게 된다면 분명히 충돌을 하게 되는 문제가 발생합니다.
이런 경우에는 OS에서의 동기화가 필요할 것이라 생각되어집니다.
Message Passing
프로세스 간에 명시적으로 메시지를 주고 받는 방식의 통신입니다.
대표적인 예시는 아래와 같습니다.
- IP Address + Port를 이용한 Socket 통신
- Pipe / Named Pipe
- Message Queue
- Domain Socket
이 방식들 모두 공통적으로 메모리를 공유하지 않으며 OS 또는 커널을 통해 메시지를 전달한다는 특성을 갖게 됩니다.
ContextSwitching의 관점에서
컨텍스트 스위칭이란 무엇일까요? 컨텍스트 스위칭이란 집을 바꿔 들어가서 열쇠/가구 배치/주소록을 전부 갈아끼운다라고 생각하시면 됩니다. 프로세스 Context Switching이란 CPU가 현재 실행 중인 프로세스를 중단하고 완전히 다른 프로세스로 실행 주체를 교체하는 과정을 의미합니다.
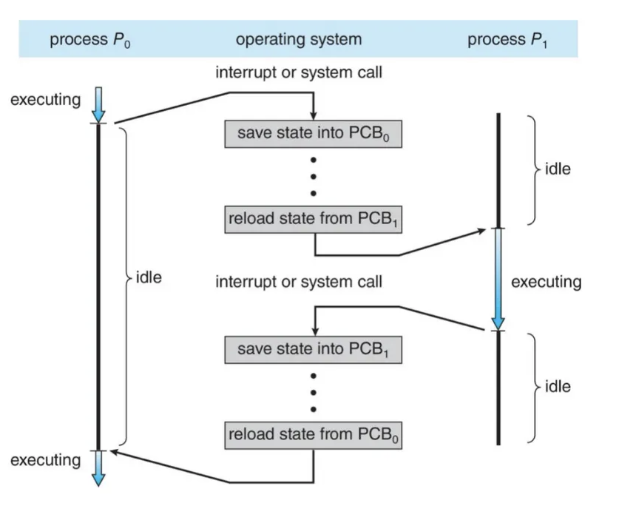
그렇다면 흔히들 컨텍스트 스위칭이 비싸다라고 하는데, 왜 비싼걸까요?
프로세스 컨텍스트 스위칭은 실행환경 전체를 바꾸게 됩니다. 주소 공간을 교체해야 하며, TLB가 무효화될 수 있습니다. 또한 이로 인해 CPU 캐시의 지역성이 깨지게 됩니다. (L1/L2 캐시 miss가 증가합니다.)
크롬은 어떤 구조로 동작하고 있을까요?

저희가 잘 쓰는 크롬은 기본적으로 멀티프로세스 구조이기는 하나, 잘 들여다보게 되면 멀티 프로세스 + 멀티 스레드 구조로 동작하고 있습니다. (부연 설명)
Thread는 무엇일까요?

하나의 목적을 가진 작업을 여러 개로 나누어 병렬(혹은 병행) 처리하기 위한 실행 단위가 바로 스레드입니다.
스레드는 독립적인 존재가 아니라 프로세스의 자원을 공유하는 실행 흐름입니다.
단일 스레드 환경에서는 프로세스 안에서 실행 흐름이 하나 뿐입니다.
이때 위 사진을 통해 구조를 파악해보면, 스레드가 직접 가지게 되는 것은 Register와 Stack이 있습니다.
이외에는 프로세스 내에서 공유되고 있는 것을 알 수 있습니다.
그 옆의 사진이 MultiThread인데, 딱 보기에도 자원의 양이 많아보이기에 처음에는 무조건 좋다라고 생각을 할 수 있지만,
공유 메모리가 엄청 큽니다. 그 큰 영역을 자주 쓰게 되고, 쓸 때마다 동기화가 필수적인 작업이 됩니다.
동기화에 대한 부담이 커지게 되는 것입니다.
Java에서 말하는 Thread는 무엇인가?

스레드는 프로세스 내부의 실행 단위이며, 멀티스레드는 공유 메모리 + 동기화 비용을 함께 가져온다고 이야기했습니다.
저는 여기서 아래와 같은 질문이 나오게 되었습니다.
Java에서 사용하는 Thread는 OS 스레드인가?
Java Thread = Kernel Thread 인가?
이 질문을 해결하고자 다시 한 번 공부를 해보기 시작했습니다.
여기서부터 나오는 내용은 아래의 테크블로그를 참조하였습니다.
https://techblog.woowahan.com/15398/
Thread에도 종류가 있다!
스레드는 구현 방식에 따라 크게 두 가지로 나뉩니다.
User-level Thread 와 Kernel-level Thread입니다.
여기서 잠깐!!
User-level Thread란?
커널이 모르는 스레드를 이야기하며, 스레드 관리가 유저 영역의 런타임이 담당하고 있는 스레드입니다.
커널 입장에서는 하나의 프로세스만 보이게 됩니다. 한 스레드가 블로킹되면 결국 전체가 멈추게 된다는 문제가 있습니다.
Kernel-level Thread란?
커널이 직접 관리하는 스레드를 뜻하며 스케줄링 단위가 스레드가 되고, 각 스레드가 커널 스레드 테이블에 등록됩니다.

기존 Java의 스레드 모델은 Native Thread로, Java의 유저 스레드를 만들면 Java Native Interface(JNI)를 통해 커널 영역을 호출하여 OS가 커널 스레드를 생성하고 매핑하여 작업을 수행하는 형태였습니다. 허나, 기술이 발전해 나가면서 요청량이 급격하게 증가하는 서버 환경에서는 갈수록 더 많은 스레드 수를 요구하게 되었습니다. 스레드의 사이즈가 프로세스에 비해 작다고 해도, 스레드 1개당 1MB 사이즈라고 가정하면, 4GB 메모리 환경에서도 많아야 4,000개의 스레드를 가질 수 있습니다. 이런 한계를 겪던 서버는 더 많은 요청 처리량과 컨텍스트 스위칭 비용을 줄여야 했는데, 이를 위해 나타난 스레드 모델이 경량 스레드 모델인 Virtual Thread입니다.

여기서 가장 큰 특징은 Virtual Thread는 컨텍스트 스위칭 비용이 저렴하다는 것입니다.
Virtual Thread는 JVM에 의해 생성되기 때문에 시스템 콜과 같은 커널 영역의 호출이 적고 메모리 크기가 일반 스레드의 1%에 불과합니다. 좀 더 자세히 들여다 보겠습니다.
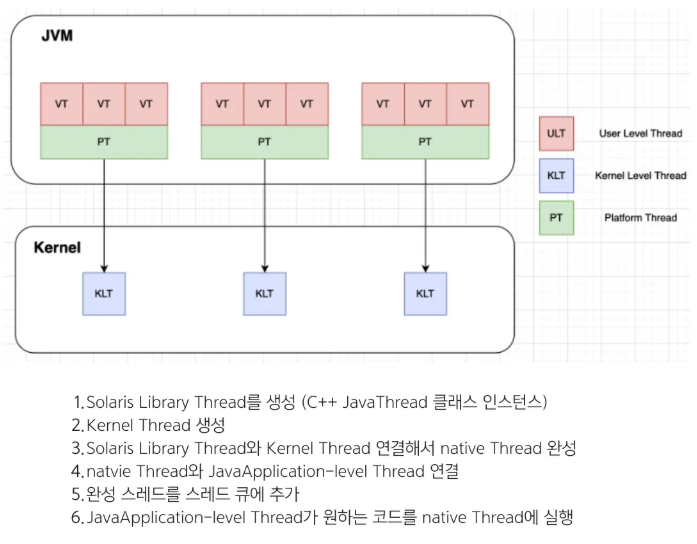
Jni Native Thread를 우선 만들고, 이를 Java Application-level의 Thread와 연결합니다.
완성된 스레드를 스레드 큐에 추가하여 Java Application-level Thread가 원하는 코드를 native Thread에 실행합니다.
아래는 Oracle 공식문서에 나와있는 내용입니다.

결론적으로는 JVM 자체적으로 Virtual Thread를 스케줄링하고 컨텍스트 스위칭 비용이 줄어 효과적으로 운영 가능하도록 만든 것입니다.
Virtual Thread 내에서 synchronized block을 사용하거나 JNI를 사용해 native 메소드를 사용하게 되면, Virtual Thread가 Platform Thread에 고정되어 장점 활용이 불가합니다.
그럼 다시 돌아가서 앞서 말씀드렸던 문제에 대해서 답변해보겠습니다.
- 멀티 스레드 환경에서 스레드를 많이 쓸수록 항상 어플리케이션의 성능이 좋아질까요?
- 어플리케이션을 수행하는 관점에서는 어떨까요?
멀티스레딩의 전제는 작업을 잘게 나눠 동시에 실행할 수 있어야 한다는 것입니다. 하지만 모든 어플리케이션이 이 조건을 만족하지는 않습니다. 예를 들면, 작업간의 의존성이 강한 경우, 순차 실행이 무조건 일어나야하는 로직, 공유 상태가 많아 동기화가 빈번한 구조들이 이에 해당할 것 같습니다. 이 경우에는 스레드를 많이 만들더라도 실제로 동시에 실행 가능한 작업 수에는 한계가 있을 것 같습니다.
- Context Switching 관점에서는 어떨까요? (CPU 코어가 고정이라는 전제를 합니다.)
CPU 코어 수가 고정된 상태에서 스레드 수를 계속 늘리면 Context Switching 비용이 성능의 병목이 될 수 있습니다.
Context Switching이 일어나는 동안 어플리케이션 코드는 전혀 실행되지 않기 때문입니다.
어플리케이션 로직과 직접적인 관련은 없지만 멀티스레딩을 위해 필연적으로 발생하는 간접 비용입니다.
즉, Context Switching의 빈도가 증가하게 되면 이로 인한 Overhead가 증가할 것이고 어느 시점부터는 스위칭 비용이 더 커지는 순간이 오게 되며 성능 한계가 올 것 같습니다.
- CPU Bound 와 I/O Bound의 관점에서는 어떨까요?
CPU Bound 작업의 경우 연산 자체가 무거운 작업이며 CPU의 사용률이 높은 작업을 일컫습니다.
이 경우에는 스레드 수 = CPU 코어 수 정도가 최적이며 그 이상 늘린다고 하더라도 코어당 경합 스레드가 늘어나며 Context Switching이 증가하고 이로 인해 오히려 성능이 저하됩니다.
반면에, I/O Bound 작업의 경우 CPU가 놀고 있는 시간이 많기에 스레드를 코어 수보다 크게 늘리는 것이 유리할 수는 있습니다. 다만 여기서도 무한정 늘리게 되면 결국 스레드 관리 비용과 메모리 사용량, 스케줄링 오버헤드가 오게될 것 같습니다. - 프로젝트를 진행하며 비동기처리를 진행하신 분들이 많이 계실텐데, @Async 어노테이션을 통한 비동기처리를 하셨을텐데, 그 때 thread-pool 설정을 하셨나요?
- 하셨다면 어떻게 하셨나요? 만약 thread-pool 설정이 없었다면 어떻게 동작했을까요?
Spring에서 @Async 어노테이션을 사용하지만 별도의 설정을 하지 않은 경우 SimpleAsyncTaskExecutor가 사용됩니다.
이 Executor의 가장 큰 특징은 요청이 들어올 때마다 새로운 스레드를 생성하는 것입니다. 즉, 스레드를 재사용하지 않으며 작업마다 매번 새로운 스레드를 생성합니다.
- 왜 설정을 안하면 문제가 생길까요?
스레드 하나를 생성할 때마다, Stack 메모리를 할당하고, 커널 스레드를 생성하고 스케줄링을 등록하는 작업이 필요합니다.
요청이 많아질수록 스레드 생성/삭제가 반복되며 CPU와 메모리 자원이 낭비되게 되는 것입니다.
또한, 최대 스레드 수, 큐 크기 등을 정해놓은 바가 없기에 동시에 수백, 수천개의 스레드가 생성될 수 있고 컨텍스트 스위칭이 폭증하여 결국 성능 저하 또는 장애로 이어지게 됩니다.
- private 메소드에서는 비동기로 해당 메소드가 작동할 수 있을까요?
이 질문은 Spring AOP와 직접적인 관련이 있는 질문인데, Spring은 proxy기반으로 동작합니다.
Spring이 Bean을 감싸는 Proxy 객체를 만들고, 외부에서 해당 메소드를 호출할 때 Proxy가 개입하여 비동기 실행을 처리합니다.
하지만 private 메소드의 경우 클래스 외부에서 호출도 불가이기에 proxy가 이를 가로챌 수가 없습니다.
그래서 결국에는 동기적으로 실행됩니다. 또한, self-invocation으로 호출하는 경우에도 동일하게 proxy를 거치지 않기에 @Async는 동작하지 않습니다.
👀 마무리하며
스레드를 이해하면 컴퓨터의 세계가 보인다는 말을 들은 적이 있습니다.
결국 모든 시스템은 스레드를 기반으로 돌아가기 때문일 것 같습니다.
'Study' 카테고리의 다른 글
Contents
소중한 공감 감사합니다