Study
(CS Study) Redis의 핵심 - Key 관리 기법과 영속성
- -
👀 들어가기 전에
Redis를 단순 캐시로만 사용할 때는 사실 데이터가 날아가도 큰 문제가 없습니다.
하지만, 세션, 장바구니, 게임 진행 상태, 재고 상태 처럼 비즈니스에 중요한 데이터를 Redis에 보관하는 순간부터는
날아가는 순간, 큰일납니다. 서버가 재시작 되거나, 전원이 꺼진다면? 데이터가 모두 증발해버립니다.
또한 수백만 개의 키가 쌓인 운영환경에서 특정 키를 조회하겠다고 잘못된 명령 하나를 실행했다가
서비스 전체가 멈추는 장애로 이어질 수도 있습니다. (실제 아래 쿠팡 사례, 카카오 기사 참조)
https://zdnet.co.kr/view/?no=20131119174125
카카오 "레디스, 잘못쓰면 망한다"
국민메신저 카카오톡 개발 업체인 카카오가 웹애플리케이션 서비스를 만드는 개발자들을 대상으로 오픈소스 기술 '레디스(Redis)' 활용 경험을 소개했다. 우수 활용사례가 아니라 절대 하면 안
zdnet.co.kr
(카카오 기사)
https://www.digitaltoday.co.kr/news/articleView.html?idxno=212880
쿠팡, 전체 품절?...시스템 오류로 주문 불가 - 디지털투데이 (DigitalToday)
전자상거래업체 쿠팡에서 판매 중인 모든 상품이 24일 오전 '품절'로 뜨며 주문에 어려움을 빚고 있다. 쿠팡은 오류가 발생한 원인을 파악 중이라고 밝혔다.쿠팡은 오늘 오전부터 판매 중인 모든
www.digitaltoday.co.kr
(쿠팡 사례)
이번 글에서는 그렇기에 Redis 운영에서 반드시 알고가야 할 두 가지 주제인 키 관리 기법과 데이터 영속성을 기술적으로 정리해보려 합니다.
👀 본론
1. Redis 키 관리 - KEYS와 SCAN
1) KEYS : 절대 production에서 쓰면 안되는 명령어
Redis에서 key를 검색하는 가장 직관적인 명령어는 KEYS입니다.
glob 스타일의 패턴 매칭을 지원하며 와일드 카드까지 사용이 가능합니다.
KEYS * -- 모든 키 반환
KEYS user:* -- "user:"로 시작하는 모든 키 반환
KEYS user:[123]* -- user:1, user:2, user:3으로 시작하는 키 매칭
KEYS user:[a-z]* -- user: 다음에 소문자 알파벳이 오는 키 매칭
KEYS user:\* -- "user:*"라는 리터럴 문자열을 가진 키 (백슬래시로 * 이스케이프)
문제는 성능입니다. KEYS는 패턴에 맞는 키를 찾기 위해 데이터베이스의 전체 키를 순회합니다.
시간복잡도가 O(n)이며, 여기서 n은 전체 키 개수입니다.
더 심각한 문제는 Blocking에 있습니다.
Redis는 싱글 스레드로 동작하기 때문에, KEYS가 실행되는 동안 다른 모든 요청을 대기해야합니다.
100만개의 키를 순회하는 동안 다른 클라이언트는 응답을 받지 못하는 것입니다.
이것이 쿠팡 장애의 원인이었고, Redis 공식 문서도 production 환경에서의 사용을 명시적으로 경고하고 있습니다.
https://www.digitaltoday.co.kr/news/articleView.html?idxno=212904
쿠팡 오류 원인은 오픈소스 '레디스 DB' 때문 - 디지털투데이 (DigitalToday)
쿠팡의 서비스 오류 원인이 ‘레디스 DB’ 문제인 것으로 드러났다.24일 오전 7시경부터 쿠팡 판매 상품의 재고가‘0’으로 표시돼, 소비자는 관련 상품의 주문 및 구매할 수 없었다. 이에 쿠팡
www.digitaltoday.co.kr
(쿠팡 기사)

(출처 : https://redis.io/docs/latest/commands/keys/)
KEYS는 로컬 개발 환경에서 데이터를 확인하는 용도로만 사용해볼 수 있을 것 같다라는 생각이 들었습니다.
2) SCAN : KEYS의 대안
SCAN은 커서기반으로 키를 조금씩 나눠서 반환하는 방법입니다.
KEYS의 문제를 근본적으로 해결합니다.
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
동작 방식은 다음과 같습니다.
첫 호출은 cursor 0으로 시작하고, Redis는 일부 키와 함께 다음 커서 값을 반환합니다.
반환 형식은 두 요소의 배열로, 첫 번째 요소가 다음 커서, 두 번째 요소가 키 배열입니다.


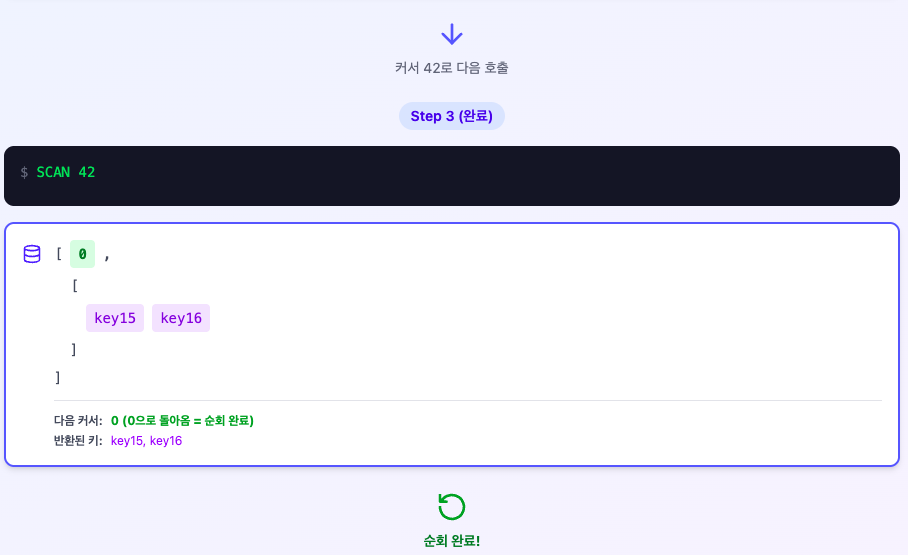
커서가 위처럼 0으로 돌아오면 전체 순회가 끝난 것입니다. 각 호출의 시간복잡도는 COUNT에 비례하지만,
COUNT는 보통 작은 상수이므로 실질적으로 O(1)에 가깝습니다.
100만 개의 키가 있어도 SCAN은 한 번에 수십 개씩 처리하기 때문에 다른 요청 처리 사이사이에 실행이 가능합니다.
단, SCAN 사용시 주의할 점이 있습니다.
RDB에서 Cursor 기반 페이징 조회를 생각해보면 유사합니다.
중복 키가 반환될 수 있습니다. 순회 도중 키가 추가,삭제 되거나, Redis 내부 해시테이블이 리사이징 되면서 키 위치가 변경되면
같은 키가 여러 번 반환될 수 있습니다. 따라서 SCAN 결과를 처리할 때는 중복 처리 로직이 필요합니다.
반면, 순회 시작 후 삭제되지 않은 키는 반드시 한 번 이상 반환됨이 보장됩니다.
3) EXISTS : 키 존재 여부 확인
EXISTS key [key ...]
키가 존재하면 1, 존재하지 않으면 0을 반환합니다.
Redis 3.0.3부터는 여러 키를 한 번에 확인할 수 있으며 존재하는 키의 개수를 반환합니다.
동일한 키를 여러번 지정하면 중복 카운트되므로
EXISTS mykey mykey mykey
를 실행하게 되면, mykey가 존재한다면 3을 반환하게 되는 것입니다.
키의 존재 여부만 확인할때는 GET으로 nil여부를 확인하는 것보다는 EXISTS명령어가 더 적합합니다.
의도가 명확하고, String 타입이 아닌 자료구조에도 사용 가능하며 값 전체를 전송하지 않아 네트워크 관점에서도 효율적입니다.
2. Redis 영속성
1) 영속성이 필요한 이유
Redis의 가장 큰 특징은 모든 데이터를 메모리에 저장하는 것입니다.
덕분에 빠르지만 메모리는 휘발성입니다. 서버가 재시작 되면 모든 데이터가 사라지는 것이지요.
재시작 상황은 생각보다 자주 발생합니다. 보안 패치, Redis 버전 업그레이드, 서버 업데이트,
예기치 않은 전원 문제나 프로세스 종료까지.
단순 캐시라면 DB에서 다시 채우면 되니 영속성이 필요 없습니다. 하지만 로그인 세션, 장바구니, 게임 진행 상태, 결제 관련 정보처럼 Redis에만 저장하는 중요 데이터라면 이야기가 다릅니다.
그렇기에 Redis는 아래 세 가지 영속성 방식을 제공하게 됩니다.
2) 영속성 방식 1 - RDB (스냅샷)
RDB(Redis Database)는 특정 시점의 메모리 데이터 전체를 하나의 파일로 저장하는 방식입니다.
카메라로 사진을 찍듯이 순간의 상태를 그대로 포착합니다.
저장되는 파일명은
dump.rdb
이며, 압축된 바이너리 형태로 저장됩니다.
동작 방식은 아래와 같습니다.
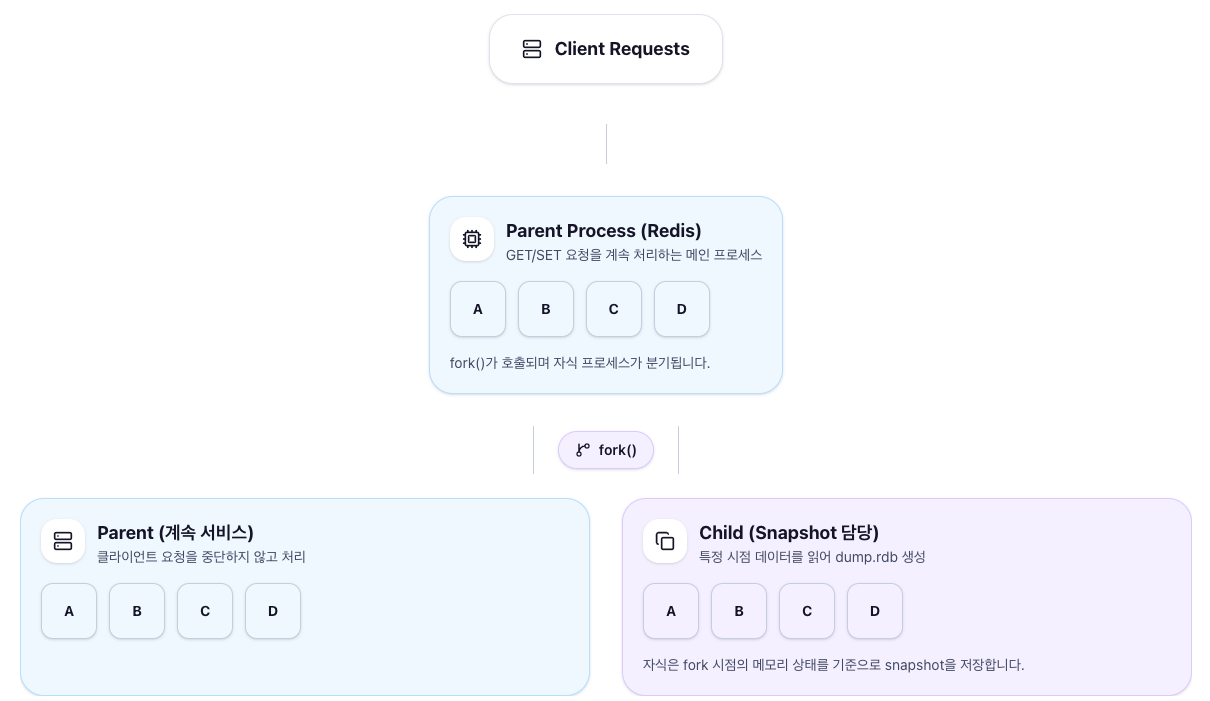
Redis는 fork 시스템 콜로 자식 프로세스를 생성하고, 자식 프로세스가 스냅샷 파일을 만드는 동안
부모 프로세스 (Redis)는 계속 클라이언트의 요청을 처리합니다.
내부적으로는 Copy-on-Write(CoW)방식을 사용해 fork 직후에는
부모와 자식이 동일한 메모리 페이지를 공유하다가

부모 측에서 쓰기가 발생할 때만 해당 페이지를 복사합니다.

이후 dump.rdb가 생성되는 것입니다.
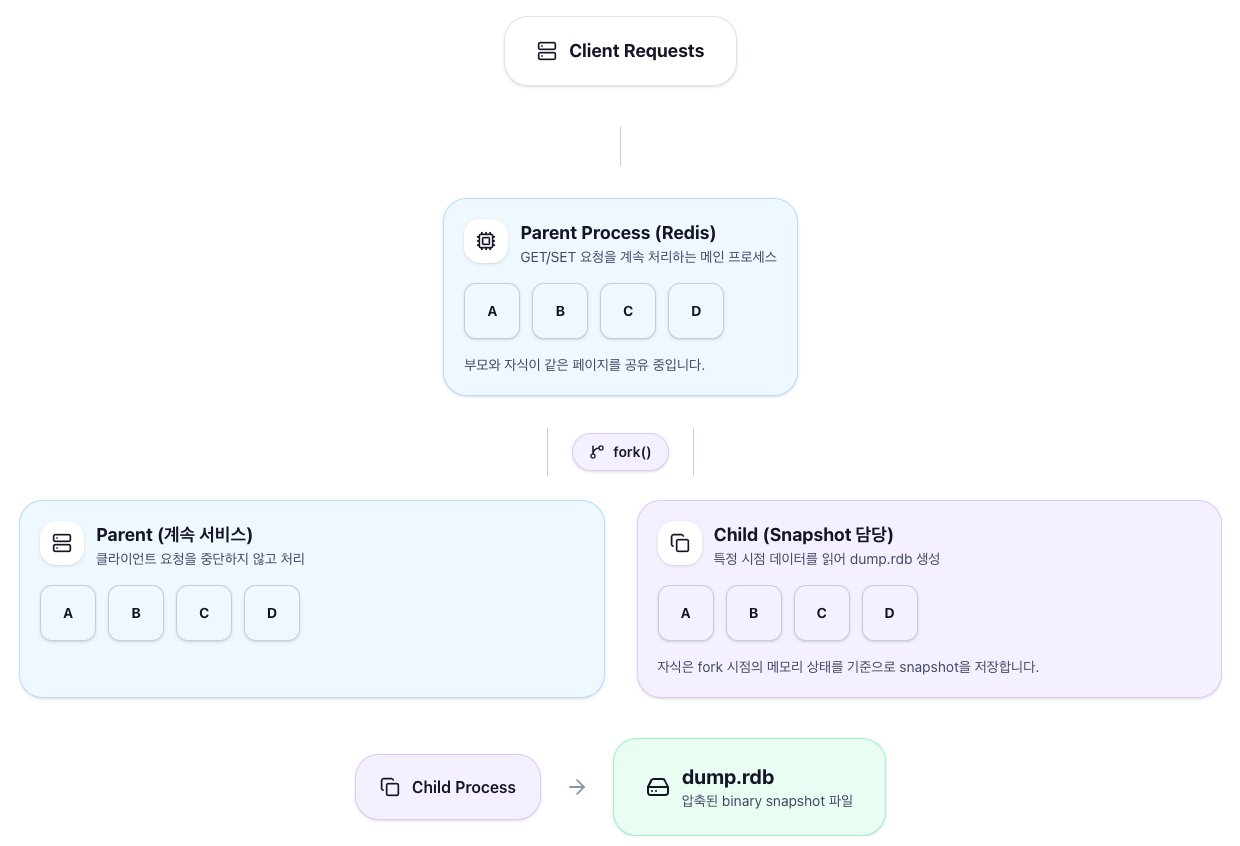
덕분에 실제 메모리 복사 비용이 최소화됩니다.
주기적으로 스냅샷 파일을 만들기에, 실시간이 아니라 특정 조건이나 간격에 따라 저장됩니다.
장점으로는 단일 binary 파일이기에 관리가 쉽고 S3같은 외부 스토리지에 날짜별 백업 보관도 용이합니다.
파일 크기가 작고 서버 재시작시 복구 속도가 빠르며 (binary 파일이기 때문에) BG save라는 백그라운드로 동작하기에
일반적인 Redis운영에 미치는 영향이 적습니다.
단점은 주기적으로 저장하기에 마지막 스냅샷 이후에 변경된 데이터는 손실되는 것입니다.
또한 fork 시점에 메모리 여유 공간이 필요하고, 데이터 규모가 크면 fork 자체가 느려질 수 있습니다.
그리고 Disk I/O가 발생합니다. (사실 어쩔 수 없는 단점인 것 같습니다 이부분은.)
3) 영속성 방식 2 - AOF (Append Only File)
AOF는 데이터를 변경하는 모든 쓰기 명령을 로그 파일에 순차적으로 기록하는 방식입니다.
RDB가 결과(스냅샷)를 저장한다면 AOF는 과정(명령 이력)을 저장합니다.
SET, LPUSH 같은 쓰기 명령은 기록되지만, GET과 같은 읽기 명령은 데이터를 변경하지 않으므로 기록되지 않습니다.
서버를 재시작하면 AOF 파일의 명령을 처음부터 끝까지 재실행하여 다운 직전의 상태를 복원합니다.
동기화 전략이 AOF의 중요한 점입니다.
파일에 쓰는 것과 디스크에 저장하는 것은 다릅니다.
OS는 성능을 위해 쓰기를 버퍼링하기 때문에, 디스크에 저장하기 전에 서버가 다운되면 버퍼의 데이터가 사라집니다.
이에 세 가지 동기화 전략이 있습니다.
- always : 매 명령마다 즉시 디스크에 동기화합니다. 가장 안전하지만, 성능이 가장 느립니다.
- everysec : 1초마다 한 번씩 동기화합니다. Redis 공식에서 권장하는 기본값입니다.
최대 1초 분량의 데이터 손실 가능성이 있지만 성능과 안전성의 균형이 좋습니다. - no : OS가 적절한 시점에 디스크에 저장합니다. 성능은 좋지만 데이터 손실 범위가 큽니다.
AOF는 append-only이기 때문에 시간이 지남에 따라 파일이 수십 GB, 수백 GB까지 커질 수 있습니다.
같은 키를 1000번 수정했다면 999개의 중간 명령은 사실상 무의미합니다.
이를 해결하기 위해 Redis는 AOF Rewrite를 통해 불필요한 명령을 제거하고 최소한의 명령만 남깁니다.
RDB와 동일하게 fork를 통해 자식 프로세스가 백그라운드로 실행하며
같은 키를 반복 수정하는 패턴이 많을 수록 이에대한 효과는 더욱 큽니다.
장점은 데이터 손실이 거의 없다는 것입니다. everysec만 사용해도 최대 1초 분량만 손실됩니다.
또한 AOF 파일은 텍스트 형식이라 실수로 FLUSHALL을 실행헀다면 서버를 즉시 정지하고
AOF 파일에서 해당 명령을 삭제한 뒤 재시작하여 복구할 수 있습니다.
단점은 텍스트 파일이기에 압축 바이너리인 RDB보다 파일 크기가 크고, 명령을 재실행하는 방식이라
복구 속도가 느립니다. 또한, always 전략 사용시 디스크 I/O로 인한 성능 저하 또한 따라오게 됩니다.
4) 영속성 방식 3 - 하이브리드 방식
RDB는 빠르지만 데이터 손실의 가능성이 있고, AOF는 안전하지만 복구가 느립니다.
그럼 두 개를 합치면?
이라는 발상에서 나온 방식이 Redis 4.0에서 도입된 하이브리드 방식입니다.
하이브리드 방식은 위 두 방식의 장점만 결합합니다.
AOF Rewrite 시 파일 앞부분은 RDB 형식의 압축 바이너리 스냅샷으로, 뒷부분은 AOF 형식의 텍스트 명령어로 구성됩니다.
책의 앞부분은 그림, 뒷부분은 글인 것과 같이 하나의 파일에 두 형식이 공존하는 것입니다.
AOF Rewrite가 시작되면, fork로 자식 프로세스를 생성합니다.
자식 프로세스는 현재 메모리 상태를 스캔하여 RDB 형식으로 파일 앞부분에 씁니다.
이 과정에서 부모 프로세스(Redis)는 계속 요청을 처리하며 새로운 명령들을 AOF 파일과 재작성 버퍼 두 곳에 기록합니다.
자식 프로세스가 RDB 쓰기를 마치면 부모로부터 재작성 버퍼를 넘겨받고, 이를 AOF형식으로 파일 뒷부분에 이어 작성합니다.
최종적으로 원본 파일을 아예 새 파일로 교체합니다.
복구 과정은 아래와 같습니다.
서버 재시작 시 파일 앞부분을 RDB 형식으로 인식해 빠르게 메모리에 로드하고,
이후 뒷부분의 AOF 명령들을 순차 재실행합니다.
AOF 부분은 Rewrite 이후 발생한 명령들 뿐이라 매우 극소량입니다.
결과적으로 대부분의 데이터는 빠른 RDB로딩으로 복구되고, 최신 소수의 명령만 AOF로 재실행됩니다.
단점도 물론 존재합니다.
파일 구조가 복잡해 직접 편집이 어렵고 Redis 4.0미만 버전과는 호환되지 않습니다.
(하지만 4.0나온지 어마어마하게 오래된 것으로 알기에...큰 문제가 될 것 같지는 않습니다)
또한, Rewrite 시 fork를 사용하기 때문에 Copy-on-Write 메모리 오버헤드가 발생합니다.
이는 순수 AOF와 동일한 문제이므로 하이브리드 방식 고유의 단점이라기보다는 상속된 특성으로 봐야할 것 같습니다.
5) 상황별 영속성 전략 선택
무조건 좋다고 다쓰는 것이 아니라, 어떤 방식을 선택할지는 항상 서비스의 특성과 요구사항에 따라 달라지게 됩니다.
a. 영속성이 필요 없는 경우가 있을 것 같습니다.
Redis를 순수 캐시 용도로만 사용한다면 영속성을 비활성화 할 수 있을 것 같습니다.
DB에서 다시 채울 수 있는 데이터라면 굳이 디스크 I/O 비용을 감수할 필요가 없을 것 같습니다.
b. 정기 백업이 필요한 경우가 있을 것 같습니다.
분석 데이터, 통계 데이터 처럼 약간의 손실이 허용된다면 RDB 방식이 적합할 것 같습니다.
단일 파일 관리가 편리하고 S3에 날짜별로 보관하기도 쉽습니다.
c. 데이터 손실을 최소화해야하는 경우가 있을 것 같습니다.
로그인 정보, 장바구니 상태, 게임 진행 데이터 처럼 손실이 사용자 경험에 직접적인 영향을 미친다면,
AOF의 everysec전략이 적합할 것 같습니다.
d. 빠른 복구와 높은 안정성이 모두 필요한 경우가 있을 것 같습니다.
이땐 하이브리드 방식을 사용하여 데이터 손실도 최소화하면서 서버 재시작 시 복구 시간도 단축할 수 있을 것 같습니다.
e. 절대적인 안정성이 필요한 경우도 있을 것 같습니다.
금융 거래 데이터나 비즈니스 핵심 데이터라면 AOF와 RDB를 동시에 활성화하는 이중 백업 전략을 고려할 수 있습니다.
두 파일을 모두 생성하여 함께 관리될 수 있도록 하는 것입니다.
👀 결론
KEYS처럼 아무 생각 없이 사용했다가 수백만건을 순회하면서 서비스 전체를 블로킹하는 상황,
영속성 설정 없이 중요한 데이터를 Redis에만 보관했다가 재시작 한 번에 모든 것이 증발하는 상황 등등
모두 충분히 실제로 일어날 수 있는 일입니다.
결국 Redis는 명령어를 단순히 사용하는 것보다 내부적으로 어떻게 동작하고 어떤 부작용을 가져오는지를 이해해야 제대로
운영하는데에 문제가 없을 것이라는 점을 다시 한 번 깨닳았습니다.
'Study' 카테고리의 다른 글
| (CS Study) Redis 기본 자료구조 깊게 파헤치기 - Set & Hash (마지막) (0) | 2026.04.10 |
|---|---|
| (CS Study) Redis List 정복 : 내부 구조부터 Queue / Stack으로의 활용까지 (0) | 2026.04.06 |
| (CS Study) Redis String 타입 완전 정리(Binary Safe부터 내부 인코딩까지) (0) | 2026.04.04 |
| (CS Study) Spring의 DI는 정말 필수적인가? 우리는 왜 Spring을 사용해야할까? (0) | 2026.04.02 |
| (CS Study) Java Virtual Thread (feat. 모던 자바 동시성 프로그래밍) (0) | 2026.03.27 |
Contents
소중한 공감 감사합니다