Project
[Sansam E-commerce] 8. MVP 이후 리팩토링 #6 : 캐싱 (캐싱에 대한 고찰)
- -
👀 들어가기 전에
우선 지금까지 진행했던 최적화 / 리팩토링 항목들을 한 번 정리하고 넘어가려 한다.
- 테스트 코드 작성 (회귀 방지 + 리팩토링 안전망 확보)
- 예외 케이스 별 서비스 로직 작성 (불필요한 재시도 / 롤백 최소화)
- 트랜잭션 범위 분리 (커넥션 점유 시간 단축)
- HikariCP 튜닝 (대기열 흡수 + 유휴 커넥션 안정성 개선)
여기까지는 단일 서비스 내부에서 할 수 있는 최선을 꽤 밀도 있게 해봤다고 생각했다. 그런데도 주요 API의 응답시간이 1~2초 (길어도 3초) 안에 안정적으로 들어오지 않았다.
이번 서비스의 특성상 주문/결제는 사용자 체감이 가장 강한 구간이고 Peak VUser 기준으로도 1~2초, 3초 내로 끝나야 한다고 판단했다.
이 기준을 만족하지 못하면 느리다고 판단하기로 했다. 이 시점부터는 코드를 차분히 훑어보며 병목이 될 수 있는 지점을 체크하고 시간복잡도를 살펴보며 어디가 병목이 될 수 있는지 더 최적화할 수 있는 부분들은 없는지에 대한 체크를 시작했고 이에 대한 고찰의 과정을 작성하려한다.
그리고 그 첫번가 캐싱이었다.
👀 본론
시간복잡도 체크로 발견한 반복 비용
public OrderResponse saveOrder(OrderRequest request){
List<OrderItemDto> items = normalize(request.getItems());
if (items.isEmpty())
throw new CustomException(ErrorCode.NO_ITEM_IN_ORDER);
//TODO: 속도 개선 가능(Ex. 비동기), DB or Network Issue
Preloaded pre = readOnlyOrderService.preloadReadOnly(request.getUserId(), items);
Map<Long, String> productImageUrl = new HashMap<>();
//TODO: 잠재적 문제 O(n)
for (Product p : pre.productMap().values()) {
productImageUrl.put(p.getId(), fileService.getImageUrl(p.getFileManagement().getId())); //O(1)
}
return afterConfirmOrderService.placeOrderTransaction(pre, items, productImageUrl);
}
}
@Service
@RequiredArgsConstructor
public class ReadOnlyOrderService {
private final UserRepository userRepository;
private final ProductJpaRepository productJpaRepository;
private final StatusRepository statusRepository;
@Transactional(readOnly = true)
public Preloaded preloadReadOnly(Long userId, List<OrderItemDto> items) {
User user = userRepository.findById(userId)
.orElseThrow(() -> new CustomException(ErrorCode.NO_USER_ERROR));
Map<Long, Product> productMap = productJpaRepository.findAllById(
items.stream().map(OrderItemDto::getProductId).toList()
).stream().collect(Collectors.toMap(Product::getId, p -> p));
// 가격 검증. 상품 가격도 읽기만 하고 들어온 요청이랑 비교만 하니께
for (OrderItemDto it : items) {
Product p = Optional.ofNullable(productMap.get(it.getProductId()))
.orElseThrow(() -> new CustomException(ErrorCode.PRODUCT_NOT_FOUND));
if (!Objects.equals(p.getPrice(), it.getProductPrice())) {
throw new CustomException(ErrorCode.PRICE_TAMPERING);
}
}
//TODO: 캐싱 (값들은 전역에서 사용되지만 자주 업데이트 되는 값은 아니니까)
Status waiting = statusRepository.findByStatusName(StatusEnum.ORDER_WAITING);
Status opWaiting = statusRepository.findByStatusName(StatusEnum.ORDER_PRODUCT_WAITING);
return new Preloaded(user, productMap, waiting, opWaiting);
}
}
코드를 돌아보며 하나하나 시간복잡도를 측정해보았고 O(n)이 걸리는 작업도 O(1)이 걸리는 작업도 있었다.
//TODO: 잠재적 문제 O(n)
for (Product p : pre.productMap().values()) {
productImageUrl.put(p.getId(), fileService.getImageUrl(p.getFileManagement().getId())); //O(1)
}
여기서 내가 주목한 건 Big-O 보다 호출 빈도 * I/O 비용이었다.
- for 루프는 O(n)이기는 하지만 n이 주문 아이템 수이기 때문에 (보통 소수) 즉시 폭발적으로 증가하지는 않는다.
- 반면 Status 조회는 서비스 전역에서 반복 호출되는 DB I/O이다
- 값은 가볍고
- 거의 읽기 전용이며
- 업데이트 빈도는 매우 낮다.
즉, 상태값 조회는 전형적인 Read-Heavy + Low-Update 데이터였다.
이걸 매번 DB에서 읽어오는게 맞나?
라는 의문이 들었고, JVM 메모리 캐싱으로 전환하는 것이 더 효율적이라고 판단했다.
왜 상태값 캐싱이 병목 후보였을까?
상태값은 이 로직에서만 쓰이는게 아니라 서비스 전반에서 광범위하게 쓰인다.
NEW, ORDER_WAITING, ORDER_PAYED와 같은 값들은 도메인 전역에서 계속해서 참조되는데 그때 마다 findByStatusName()으로 DB를 때리면 결국 아래와 같은 상황이 만들어진다.
예를 들어 목표 Peak VUser가 1,000명이고 주문 API가 동시 호출되면 (요청당 상태값 조회가 1~2회만 있어도) 순식간에 수천 건의 불필요한 DB read가 발생한다.
이는 결국에는
- 트랜잭션 시작 후 커넥션 점유 시간 증가
- 커넥션 풀 대기열 증가
- 락이 없어도 DB I/O로 인한 지연 누적
- 결국 p95 / p99에서 Tail Latency 폭발
로 이어질 가능성이 높다고 판단헀다.
그래서 상태값은 DB가 아니라 캐시(메모리)에서 꺼내는 것이 합리적이었다.
읽기 데이터는 전부 캐싱하면 빠르겠네?
반은 맞고 반은 위험한 이야기이다. (사실 그냥 말도 안되는 이야기이다.)
읽기 캐싱은 분명히 빠르지만 무작정 캐싱하면 다음과 같은 문제가 생긴다.
- 정합성 문제
캐시에 오래 남아있는 값이 DB와 달라질 수 있다.
특히 업데이트가 드물다는건 업데이트가 0이다가 아니다.
- 운영자가 상태값을 추가/수정
- 배치/마이그레이션으로 상태 재정의
- 일부 환경에서 핫픽스로 값 변경
이런 순간 캐시가 갱신되지 않으면 서비스는 오래된 상태로 동작한다. - 캐싱의 과잉 (내가 보기엔 그냥 캐시 떡칠이다.)
병목이 생겼다고 해서 무작정 읽기 데이터를 캐시로 덮어버리면 나중에는 원인 분석도 안되고 코드의 가독성도 아주 매우 많이 떨어진다.
캐시는 만능 해결법이 아니라 하나의 수단일 뿐이다.
선택에 있어 가장 중요한 것은 "무엇을 캐싱할 것인지, 왜 그것을 캐싱해야만 했는지, 실패시 어떤 보상 로직이 생길 것인지"가 함께 생각되어져야한다고 생각한다.
어떤 캐시를 사용할 것인가.
캐싱 전략은 크게 두 가지 방향을 고려했다.
- 글로벌 캐시 (Redis 등)
- 장점 : 중앙 집중식 관리, TTL 통제 용이
- 단점 : 네트워크 I/O 추가, 인프라 비용 / 운영 부담 - 로컬 캐시 (Caffeine, Ecache 등)
- 장점 : 초저지연 (메모리), 네트워크 I/O 발생이 없음
- 단점 : 인스턴스간 캐시 불일치 ,캐시 무효화 전략 필요
이번에 캐싱하려는 대상은 상태값 하나였고 이 값은 서비스 전역에서 거의 읽기 전용으로 동작한다. 데이터의 수도 10~20개 내외로 많지 않았다. 이 정도 규모의 데이터를 위해 별도의 Redis 인프라를 구축하고 네트워크 I/O 비용을 추가하는 것은 오히려 과하다고 판단했다.
그리하여 로컬 캐시 기반으로 처리하는 것이 더 단순하면서도 효과적인 적합한 선택이라고 판단했다.
로컬 캐시도 종류가 많았지만, 결론 부터 이야기하면 Caffeine 캐시를 선택했다.
Caffeine 캐시를 선택한 이유

위 자료들에 따르면, Caffeine 캐시는 읽기 위주의 워크로드에서 매우 높은 처리량을 보여준다.
다른 캐시 라이브러리에 비해 낮은 지연시간과 높은 적중률을 동시에 제공하는 것으로도 잘 알려져 있다. 특히, 이번 케이스처럼 읽기 비중이 압도적으로 높은 상태값을 다루는 상황과 잘 맞아 떨어진다고 판단했다.
추가로, Caffeine은 우수한 캐시 제거 정책을 사용하는 것도 장점이 있었다. 흔히 많이 알고 있는 Ecache가 LRU, LFU, FIFO 등의 전통적인 알고리즘을 사용하는 반면 Caffeine 캐시는 Window TinyLFU라는 정책을 사용한다. 이 방식은 LFU와 LRU의 장점을 결합해 자주 사용되거나 최근에 사용된 데이터가 캐시에서 가능한 오래 살아남도록 설계 되어있으며 실제로도 높은 적중률을 보여준다.
(추가) Window TinyLFU란?
Caffeine 캐시의 핵심은 최근성과 빈도를 함께 고려하는 점이다.
Window TinyLFU는 다음과 같이 작동한다.
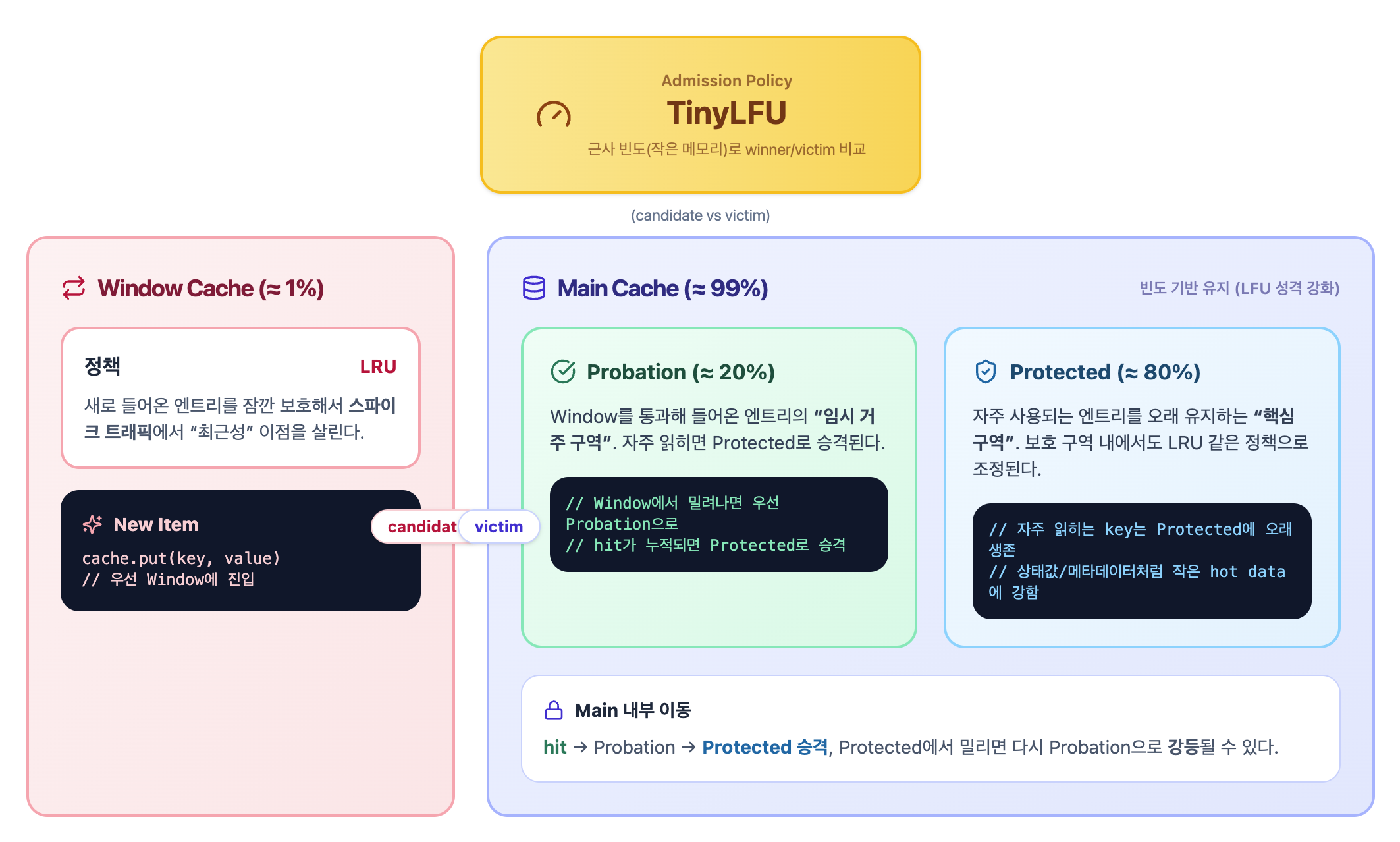
1) Window 영역
새로 들어온 엔트리를 바로 내치지 않도록 작은 윈도우 캐시 영역을 두고 최근 들어온 것들을 잠깐 보호한다.
→ 갑자기 몰리는 트래픽에서 LRU의 장점을 살린다.
2) Main 영역 (빈도 기반 유지)
윈도우를 통과한 데이터들은 Main 캐시에서 자주 쓰이는지를 기준으로 살아남는다. 여기서는 LFU의 성격이 강해진다.
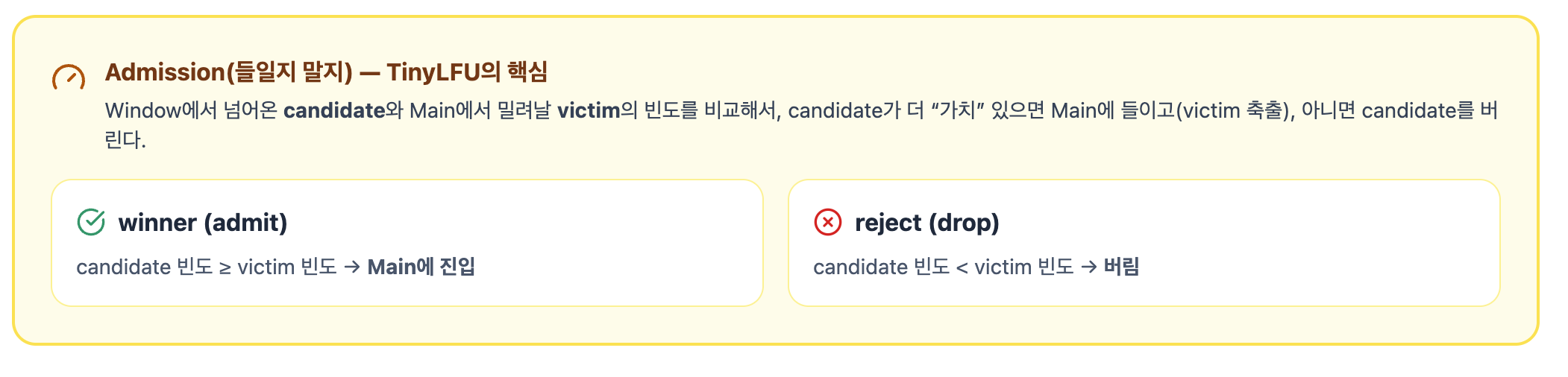
3) Admission 정책 (들일지 말지에 대한 판단)
모든 데이터를 무조건 캐시에 넣지 않고, "이 데이터를 캐시에 들일 가치가 있는가?"를 판단한다.
이때, TinyLFU는 빈도를 완벽히 세는 대신 작은 메모리로 빈도를 근사해서 판단한다.
최근 들어온 데이터는 일단 보호하되
자주 쓰이지 않으면 메인 캐시에 정착시키지 않는다.
상태값 처럼 자주 읽히는 작은 데이터에는 굉장히 잘 맞는 전략이라고 판단했다.
최근 들어온 데이터는 Window가 보호하고 자주 읽히는 작은 데이터는 Main에서 오래 생존한다.
반대로 잠깐 반짝 트래픽인 데이터는 Admission 단계에서 걸러져 캐시 오염을 줄일 수 있다.
정합성은 어떻게 가져갈 것인가.
여기서 고민을 했던 부분은 캐시를 어떻게 무효화 시킬 것인가이다.
캐시는 성능을 크게 개선할 수 있지만 잘못 쓰이면 오히려 정합성을 해친다.
상태값은 업데이트가 드물기 때문에 엄청 복잡한 실시간 동기화 전략이 필요하진 않지만 그럼에도 정합성은 맞아 떨어져야만 한다.
최종 선택 전략은 아래 두 가지를 조합하는 방식이었다.
- TTL 기반 자동 갱신
- 캐시 TTL을 24시간으로 설정
- 일정 시간이 지나면 자연스럽게 캐시 만료 → DB 재조회 - 배포 시 캐시 초기화
- 새로운 배포가 발생하면 JVM 재기동과 함께 캐시 초기화
- 신규 기능 / 상태 추가의 즉시 반영을 위함
도메인 특성으로 인해 이렇게 선택하게 되었다.
상태값 자체가 운영 중 수시로 변경되는 데이터가 아니다.
- ORDER_WAITING
- ORDER_PAYED
- CANCELED
- DELIVERING
이런 값들은 보통 새로운 기능이 추가되거나, 도메인 정책이 바뀌는 시점에만 변경된다.
즉, 상태값이 24시간 이내에 변경된다면 그 자체로 이벤트성 변경 혹은 기능 추가에 가깝다고 판단했다.
그리고 그런 경우라면
- 배포가 동반되거나
- 운영자가 명시적으로 인지하고 있는 변경일 가능성이 높다.
따라서, 최대 24시간 동안 이전 상태값을 보는 것은 비즈니스적으로도 운영적으로도 충분히 감내 가능한 범위 내라고 판단헀다.
캐시에 없는 값은?
캐시는 어디까지나 보조 수단이다.
캐시에 없다고 해서 로직이 깨지면 안된다.
그래서 상태값 조회 로직은 항상 다음 순서를 따르도록 코드를 짰다.
- 캐시 조회
- 캐시에 없으면 Repository 통한 DB 조회
- DB에도 없을 경우 예외처리
즉, 캐시에 있으면 빠르게 쓸 수 있도록, 없으면 언제든 DB로 돌아갈 수 있는 구조로 코드를 짰다.
이렇게 해야 캐시 초기화 직후, TTL 만료 이후, 혹은 예기치 못한 예외 상황에서도 서비스가 정상적으로 작동할 수 있다고 판단하였다.
캐싱 적용 결과
Caffeine 캐시를 적용한 코드는 아래와 같다.
@Service
@RequiredArgsConstructor
public class ReadOnlyOrderService {
private final UserRepository userRepository;
private final ProductJpaRepository productJpaRepository;
private final StatusCachingService statusCachingService;
@Transactional(readOnly = true)
public Preloaded preloadReadOnly(Long userId, List<OrderItemDto> items) {
User user = userRepository.findById(userId)
.orElseThrow(() -> new CustomException(ErrorCode.NO_USER_ERROR));
//동기 + O(n)
Map<Long, Product> productMap = productJpaRepository.findAllById(
items.stream().map(OrderItemDto::getProductId).toList()
).stream().collect(Collectors.toMap(Product::getId, p -> p));
// 가격 검증. 상품 가격도 읽기만 하고 들어온 요청이랑 비교만 하니까, O(n)
for (OrderItemDto it : items) {
Product p = Optional.ofNullable(productMap.get(it.getProductId()))
.orElseThrow(() -> new CustomException(ErrorCode.PRODUCT_NOT_FOUND));
if (!Objects.equals(p.getPrice(), it.getProductPrice())) {
throw new CustomException(ErrorCode.PRICE_TAMPERING);
}
}
Status waiting = statusCachingService.get(StatusEnum.ORDER_WAITING);
Status opWaiting = statusCachingService.get(StatusEnum.ORDER_PRODUCT_WAITING);
return new Preloaded(user, productMap, waiting, opWaiting);
}
}
@Service
@RequiredArgsConstructor
public class StatusCachingService {
private final StatusRepository statusRepository;
@Cacheable(cacheNames = "statusByName",key = "#name.name()", unless = "#result == null")
public Status get(StatusEnum name){
return statusRepository.findByStatusName(name);
}
}
Caffeine 캐시를 적용해 Status 값을 캐싱한 위 코드를 토대로
동일하게 Peak VUser 600명을 대상으로 E2E 피크 테스트를 진행했다.


상태값 적용 전/후를 비교해보면 P90/P95 구간에서 약 2~3초 정도 단축되는 개선 효과를 확인할 수 있었다.
특히 피크 구간에서의 응답 지연이 완만해지면서 전체적인 사용자 경험도 안정적으로 개선되는 부분을 확인할 수 있다.
👀 마치며
부하 테스트와 피크 테스트를 반복하며 어디를 손대야 할지 고민하고 그 중 무엇을 고쳐야할 지를 선택해 리팩토링하는 과정을 계속하고 있다.
정해진 답은 없고, 망망대해 같은 상황 속에서 하나씩 병목을 발견하고, 가설을 세우고, 다시 검증해 나가는 흐름의 반복이다.
그럼에도 이 과정이 나름 즐겁다. 눈에 보이지 않던 문제들이 수치와 흐름으로 드러나고 작은 선택 하나가 전체 성능 곡선에 영향을 주는 순간들을 마주할 때마다 왜 이것을 하고 있는지를 다시 느끼게 된다.
다음 글에서도 또다시 고민하고 선택하고 검증한 끝에 어떤 결과에 도달했는지를 정리해보려 한다.
'Project' 카테고리의 다른 글
Contents
소중한 공감 감사합니다