Project
[Sansam E-commerce] 9. MVP 이후 리팩토링 #7 : MSA는 언제 필요한가 (feat. 재고 비동기 처리 실험과 서버 분리 검증)
- -
👀 들어가기 전에
한동안 머리를 굴리다 보니 사고 과정이 자연스럽게 여기까지 도달했다.
"지금 이 상태에서 단일 서비스 안에서 더 깎아낼 수 있는 비용이 남아있긴 한가
테스트 코드 보강, 예외처리 흐름 정리, 트랜잭션 범위 분리, HikariCP 튜닝, 캐싱까지.
할 수 있는 최적화를 밀도 있게 진행했는데도 피크 구간의 Tail Latency (P95, P99)는 쉽게 줄지 않았다.
그래서 다음 선택지를 고민했다.
- 동기 로직 중 비동기로 분리 가능한 구간을 최대한 떼어낸다.
- 그래도 한계가 보이면 서버 분리(Scale-out)을 검토한다.
다만 이 시점에서 한가지를 분명이 하고 싶었다.
서버 분리는 "자원을 늘리면 빨라지겠지" 같은 감각으로 결정하면 안 된다.
분리는 곧 통신 비용, 정합성 전략, 운영 복잡도, 서버 비용을 함께 떠안는 선택이다.
회사에 들어갔을 때 그정도의 트래픽이 없는데 무작정 자원부터 늘리고 보는 것은 회사 재정의 낭비라 생각한다.
즉, MSA는 근거를 갖춘 비용 지불이어야만 한다.
(요즘 유독 MSA 프로젝트가 난무하여 적어본 생각이다.)
이 글은 "서버를 분리해야하나?"라는 질문에 답하기 위해,
내가 어떤 근거를 쌓아갔고 왜 다시 단일 서버로 돌아왔는지에 대한 기록이다.
👀 본론
재고 이벤트를 비동기로 분리할 수 있을까?
다음 단계에서는 동기 처리 중 응답을 늦추는 요소를 먼저 분리해보기로 했다.
주문 / 결제 플로우를 뜯어보니 비동기 처리 대상으로 적합한 구간이 두 가지였다.
- 재고 차감
재고 차감의 책임은 본질적으로 재고 도메인에 있다.
주문 서비스 입장에서는 재고를 차감해야 한다는 사실(이벤트)만 전달하고,
실제 차감 처리는 별도의 워커/컨슈머가 비동기로 수행해도 된다. - 결제 후처리
결제 이후 발생하는 알림 발송, (향후 도입될 수 있는) 배송 시작 같은 후처리 작업은 사용자에게
"승인 응답"을 빠르게 반환한 뒤 백그라운드로 밀어내기 좋은 후보들이다.
이렇게 비동기화를 통해 목표로 한 것은 아래와 같다.
사용자 응답 (주문 / 결제 승인)과 부가 작업을 분리해서
1차 응답을 빠르게 수렴시키고, 무거운 작업은 비동기 큐에서 흡수 시키자.
비동기 처리는 아무렇게나가 아니라 정합성을 가진 채로 해야 한다
여기서 중요한 포인트는 비동기화 대상이 언제 처리돼도 상관없는 작업이 아니라는 점이다.
- 재고 차감 : 같은 상품에 대해서 순서 / 동시성 제어가 필요하다. (oversell 방지)
- 결제 후처리 : 순서 자체는 덜 중요할 수 있어도 정합성이 핵심이다.
그래서 단순히 @Async로 스레드만 떼는 방식보다 큐 기반(FIFO)으로 순서와 버퍼링을 함께 가져가는 구조가 자연스럽게 떠올랐다.
- FIFO로 먼저 들어온 이벤트부터 처리
- 큐가 버퍼 역할을 하여 피크 트래픽을 흡수
- 실패 시 재시도/ 격리(DLQ) 설계 가능
이 관점에서 메시지 큐를 도입하는 것이 합리적이다고 판단하였다.
서버 분리까지 생각이 뻗어나간 이유
Peak VUser 500 환경에서도 서버가 뻐근해지는 모습을 보면서 '단일 서버 안에서 동기/비동기를 모두 해결하려 하면 결국 같은 자원을 서로 잡아먹는다'는 생각이 들었다.
즉, 비동기로 분리해도 결국
- 같은 JVM
- 같은 CPU
- 같은 Connection Pool
- 같은 DB접근
안에서 경쟁한다.
그래서 다음 질문이 따라왔다.
재고 처리를 담당하는 자체 자원을 분리하면 어떨까?
재고 서버를 별도로 떼면 최소한 스레드 / 커넥션 / CPU 경합을 줄일 수 있지 않을까?
서버 분리가 정답이라는 것이 아니다. 근거를 만들기 위한 실험으로 접근했다.
서버 분리 시 통신 방식 선택
서버를 분리하면 기존의 인프로세스 호출이 서버 간 통신이 된다.
이때 후보는 다음과 같다.
- HTTP : 결국 동기 요청/응답 → 비동기 목적과 충돌
- WebSocket : 장기 연결 유지 / 재연결 / 장애 처리 부담이 크다.
- 인프로세스 이벤트 : 서버 분리가 되는 순간 아무 의미 없다.
- 메시지 큐 : 비동기 전달, 버퍼링, 재시도 / 격리 설계가 가능하다.
따라서 서버 간 비동기 통신은 메시지 큐로 결정했고, 초기 검증 단계에서는 RabbitMQ를 선택했다.
RabbitMQ vs Kafka : 지금 필요한 것은?
RabbitMQ와 Kafka의 비교는 늘 나오지만, 중요한건 지금 현재 상황에서 무엇이 필요한가이다.
- RabbitMQ : 메시지 브로커, 라우팅/교환 패턴, 작업 큐 스타일에 적합하다.
- Kafka : 이벤트 로그/스트리밍 플랫폼, 파티션 기반 확장성, 생태계(Kafka Streams, Connect)가 매우 편리하다.
이번 단계의 목표는 대규모 스트리밍 플랫폼 구축이 아니라 재고 이벤트 비동기 처리의 효과를 빠르게 검증하는 것이었기에
RabbitMQ로 먼저 실험했고 이후 Kafka도 확장성 관점에서 검토했다.
결과 1) 단일 서버 + RabbitMQ 비동기화

이를 이전에 했던 테스트 결과와 비교해보면 아래와 같다.
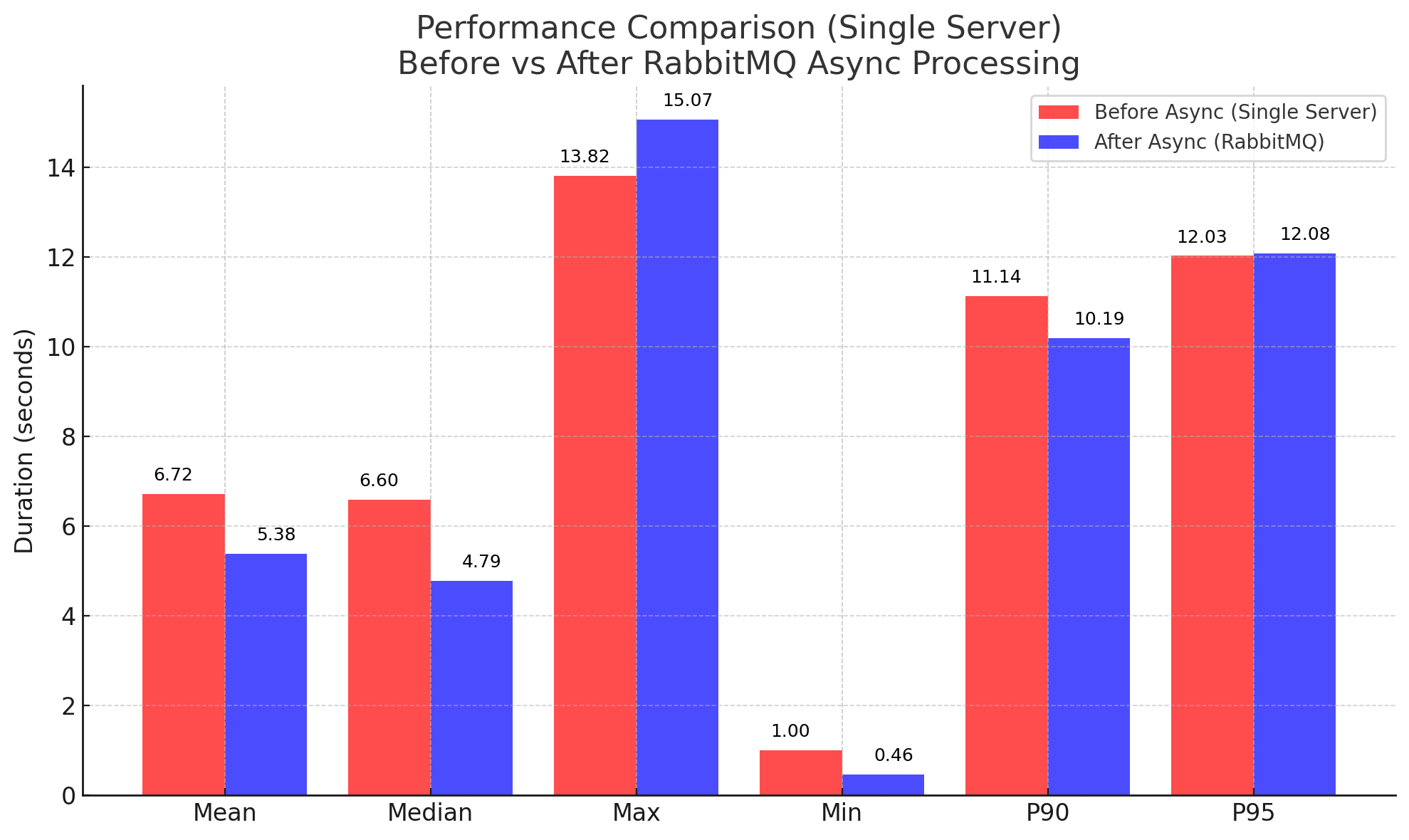
단일 서버 환경에서 재고/후처리 작업을 큐로 밀어넣고 비동기 처리를 했더니
- 평균, 중앙값은 분명히 개선
- 사용자 체감도 좋아졌다.
하지만, 피크 구간에서 P95, Max tail latency가 여전히 남아있다.
비동기 처리로 평균은 줄었지만 병목 자원이 동일한 상황에서 피크 구간 Tail Latency는 쉽게 줄지 않았다.
결과 2) 재고 서버 분리 + RabbitMQ 비동기 통신

그래서 재고 도메인을 위 사진처럼 별도 서버로 분리했다.
- API 서버 : 주문/결제 승인 응답 책임에 집중
- Stock 서버 : 재고 차감 및 후처리 전담
- 통신 : RabbitMQ 비동기 메시지

단일 서버로 진행했을 때와 비교해보면 확연히 차이를 알 수 있다.

stock consumer가 별도 JVM로 분리되며 커넥션 풀 starvation이 해소됐다.
특히 VUser 600 구간까지 극단적인 지연 없이 응답이 수렴했고,
Max 응답 시간이 줄면서 Tail Latency가 개선되는 모습이 보였다.
여기까지 보면 "서버 분리가 답"처럼 보이지만 이 단계에서 끝나기에는 한 가지가 걸렸다.
서버 분리 비용을 지불할 만큼 지금 당장 필요한가?
여기서 멈추기에는 근거 없는 MSA가 되어버린다.
서버 분리는 성능을 올릴 수는 있다. 하지만, 성능이 조금 좋아졌다는 점만으로 분리를 확정하기에는 위험하다고 판단헀다.
왜냐면 분리하는 순간부터 시스템은 아래와 같은 비용이 들어간다.
- 메시지 유실/ 중복/ 순서 문제 → 정합성 전략 필요
- 장애 전파 / 복구 플로우 필요
- 결국 개발 / 운영 생산성 비용 증가
즉, 분리는 성능이 좋아졌으니 OK가 아니라 그 비용을 지불할 만큼 지금 당장 필요한가에 대한 고민을 해야한다.
(추가) RabbitMQ를 썼을 때 얻었던 운영적인 이점
이번 단계에서 RabbitMQ를 선택했던 가장 큰 이유는 비동기 처리를 운영 가능한 형태로 만들 수 있었기 때문이다.
RabbitMQ에서 컨슈머는 메시지를 처리한 뒤 ACK을 보내고, 브로커는 그 때 메시지를 큐에서 제거한다.
반대로 처리 실패시 NACK / Reject로 메시지를 다시 큐로 돌리거나 설정에 따라 DLQ로 격리 가능하다.

이 구조 덕분에 최소한 아래는 쉽게 확보할 수 있었다.
- 메시지 처리가 실패해도 유실되지 않도록 DLQ에 쌓기 (물론 메모리에 올려지기에 유실 가능성이 아예 없다고 할 수는 없다.)
- 실패 원인을 추적하고 재처리 후 복구 루트를 운영적으로 가져가기 편안함
물론 이건 DB 트랜잭션 같은 강한 일관성은 아니지만 재고 이벤트 비동기 처리 같은 작업 큐의 성격에는 이게 더 현실적이었다.
(추가) Kafka 실험
여기서 멈추지 않고 확장성의 관점에서 Kafka도 직접 실험해 보았다. (단일 컨슈머 환경이었다.)
Kafka Streams까지 사용해 이벤트 기반으로 정합성을 잡는 흐름을 실험해봤다.
문제는 주문/결제 도메인에서는 결국 아래와 같은 요구사항이 생긴다.
재고 차감이 확정되기 전에는 결제를 승인하면 안 된다.
Kafka로 재고차감을 구현해놓게 되면, 결제 서비스에서 재고 차감 결과 이벤트를 확인할 수 밖에 없다.
그래서 흐름은 아래와 같이 설계 되었다.
- 주문 생성 → Kafka 이벤트 발행
- 재고 서비스 : 재고 확인 및 차감 → 결과 이벤트 발행
- 결제 서비스 : 재고 결과를 확인한 후 결제 승인 진행
이 구조 자체로 정합성을 확보할 수는 있다.
하지만 동시에 실패하는 시나리오가 구조적으로 늘어나면서 보상 트랜잭션(Saga 패턴)이 사실상 필수로 따라 붙었다.
즉, "메시지 브로커만 바뀌었다"가 아니라 시스템 전체가 이벤트 기반 분산 트랜잭션 모델로 넘어가는 비용을 감당해야 했다.
성능 결과는? Kafka가 안정적이긴 하나, 절대적으로 이득이라고 보기 어려웠다.
Peak VUser 600환경에서 피크테스트를 E2E로 진행했을 때, RabbitMQ 기반 비동기 처리와 Kafka 기반 구조를 비교해보니 아래와 같았다.

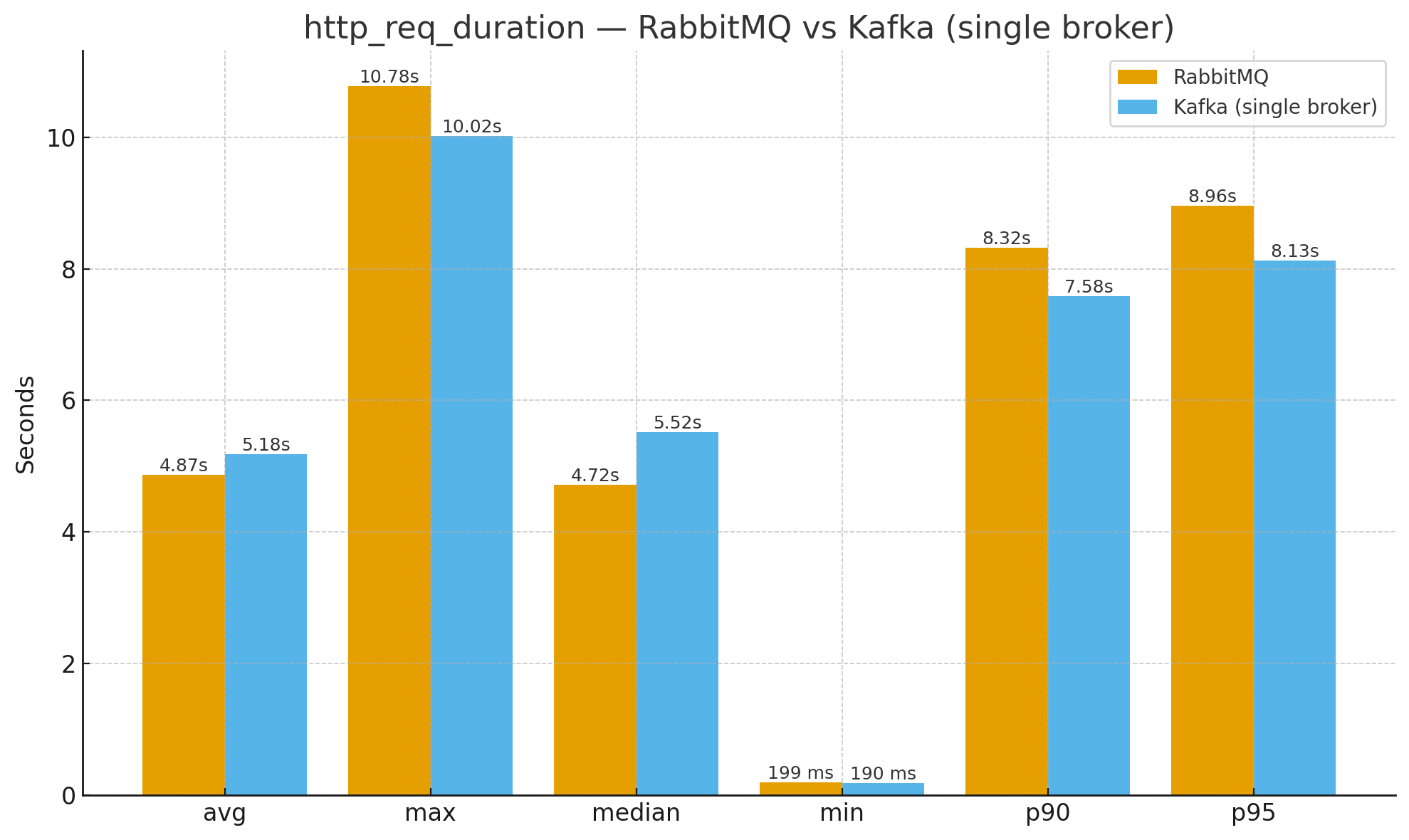
- 평균 응답시간은 Kafka 기반에서 다소 증가
- 반면 P90 / P95 같은 Tail Latency 구간에서는 Kafka가 상대적으로 더 안정적
이라는 특성이 관측된다.
다만 전체 플로우를 고려해보면 Kafka 기반 분산 이벤트 처리에서는
- 도메인 간 통신 비용 증가
- 결과 대기 로직 추가
- 보상 트랜잭션 (Saga) 운영 비용 증가
가 함께 따라오게 되었다.
다시 돌아보며
차분히 프로젝트를 다시 돌아본 결과, 아직 단일 서버 환경에서 실험해보지 않은 영역들이 남아있다는 점을 깨달았다.
특히 재고 차감의 경우
- DB 종류 변경
- 락 전략 변경
등, 서버를 나누기 전에 먼저 검증해야 할 선택지들이 충분히 남아 있었다.
그래서 현재 단계에서는 구조를 먼저 복잡하게 가져가기 보다는 단일 서버에서 재고를 어떻게 가장 효율적으로 처리할 수 있는지에 집중하기로 결정했다.
👀 마무리하면서
서버 분리 실험을 통해 분리가 주는 이점과 분리가 요구하는 비용을 직접 체감할 수 있었고,
그 결과 지금 단계에서의 최적화 우선순위는 서버 분리가 아니라 DB레벨에 있다는 결론에 도달했다.
병목의 본질을 규명하기 전 분리는 단순히 비용만 키울 수 있다는 점을 체감하게 되었다. 그래서 분리 실험으로 이득과 비용을 직접 체감한 뒤 ROI가 더 높은 DB와 Lock 최적화 실험으로 우선순위를 돌렸다.
다음 포스팅은 다시 단일 서버로 돌아가서 재고 차감의 부분들을 어떻게 변경해 나갔고 어떻게 peak VUser 1000을 달성한지에 대해서 이야기 해보도록 하겠다.
'Project' 카테고리의 다른 글
| [Sansam E-commerce] 11. MVP 이후 리팩토링 #9 : 주문 조회 성능 최적화 (1) | 2026.01.01 |
|---|---|
| [Sansam E-commerce] 10. MVP 이후 리팩토링 #8 : 단일 서버에서 Redis기반 재고 관리 (0) | 2025.12.31 |
| [Sansam E-commerce] 8. MVP 이후 리팩토링 #6 : 캐싱 (캐싱에 대한 고찰) (0) | 2025.12.29 |
| [Sansam E-commerce] 7. MVP 이후 리팩토링 #5 : HikariCP 튜닝 (0) | 2025.12.29 |
| [Sansam E-commerce] 6. MVP 이후 리팩토링 #4 : Order 트랜잭션 분리 & DB Indexing을 통한 최적화 & 테스트 툴 변경 (0) | 2025.12.26 |
Contents
소중한 공감 감사합니다