Study
(CS Study) 트랜잭션의 격리수준 어디까지 알고 계십니까?
- -
👀 들어가기 전에
이번 주에 면접 스터디를 진행하던 중 트랜잭션의 격리수준에 대한 질문을 받게 되었습니다.
그 순간 문득 이런 생각이 들었습니다.
나는 트랜잭션 격리 수준을 정말 이해하고 있는 것인가?
학부 과정에서 데이터베이스 수업을 통해 격리 수준에 대해 배운 기억은 있었지만 돌이켜보면 정의만 알고 있을 뿐
실제로 어떻게 동작하는지 깊이 있게 고민해본 적은 없었습니다.
이번 글에서는 면접 스터디에서 출발한 질문들을 계기로 트랜잭션 격리 수준을 학부 수준의 정의에서 시작해 실제 DB 내부 동작까지 파고들어 정리해보려 합니다.
👀 본론
들어가기 전에) 트랜잭션 격리 수준에 대해 알고 계십니까?
트랜잭션 격리 수준이라고 하면 흔히 학부 데이터베이스 수업에서 배운 4가지 격리 수준을 떠올리게 됩니다.
대표적으로 다음 네가지가 있습니다.
- Serializable : 모든 트랜잭션을 순차적으로 실행한 것과 동일한 결과를 보장
- Repeatable Read : 하나의 트랜잭션에서 동일한 데이터를 여러 번 읽어도 같은 값을 보장
- Commited Read : 다른 트랜잭션에서 커밋된 데이터만 읽기 가능
- Uncommited Read : 다른 트랜잭션에서 커밋되지 않은 데이터도 읽기 가능
격리 수준은 위에서 아래로 갈수록 동시성은 높아지지만, 데이터 일관성 보장은 약해집니다.
여기까지 데이터베이스 수업에서 한 번쯤은 들어본 내용입니다. 하지만 이 정의만으로 제가 궁금했던 점에 대한 대답이 되기는 어렵습니다.
DBMS는 도대체 어떤 방식으로 이런 격리 수준을 구현하는 걸까?
이 글은 이 질문에 답하기 위해 궁금한 부분을 해결하는 과정을 기록했습니다.
즉, 격리 수준을 메커니즘으로 이해하는게 목표입니다.
1) DBMS마다 기본 격리 수준이 다르고, 같은 이름이더라도 동작이 다르다?
먼저 대표 DBMS의 격리 수준부터 알아보았습니다.
- MySQL (InnoDB) : Repeatable Read
- PostgreSQL : Read Commited
- Oracle : Read Commited
여기서 중요한 포인트는 같은 이름의 격리 수준이라도 내부 구현은 DBMS마다 다르다는 점입니다.
예를 들어 Repeatable Read라는 이름은 같더라도
- MySQL (InnoDB) : MVCC + Locking 조합으로 일관성을 만들고
- PostgreSQL : Repeatable Read는 사실상 Snapshot Isolation에 가깝게 동작합니다.
즉, Repeatable Read면 Phantom Read가 막히겠지? 같은 이름을 통한 추측은 DBMS에 따라 틀릴 수 있다는 것입니다.
예를 들면 PostgreSQL에서의 Repeatable Read는 사실상 Snapshot Isolation입니다.
즉 동작 방식이
트랜잭션 시작 시점의 snapshot 고정 → 모든 Select는 그 snapshot 기준으로 읽음 이 되는 것입니다.
아래와 같은 상황이 발생할 수 있는 것입니다.
Transaction 1 :
1) BEGIN;
2) SELECT COUNT(*) FROM orders WHERE price > 100;
결과 : 5


Transaction 2 :
1) INSERT INTO orders(price) VALUES (200);
2) COMMIT;

Transaction 1 :
1) SELECT COUNT(*) FROM orders WHERE price > 100;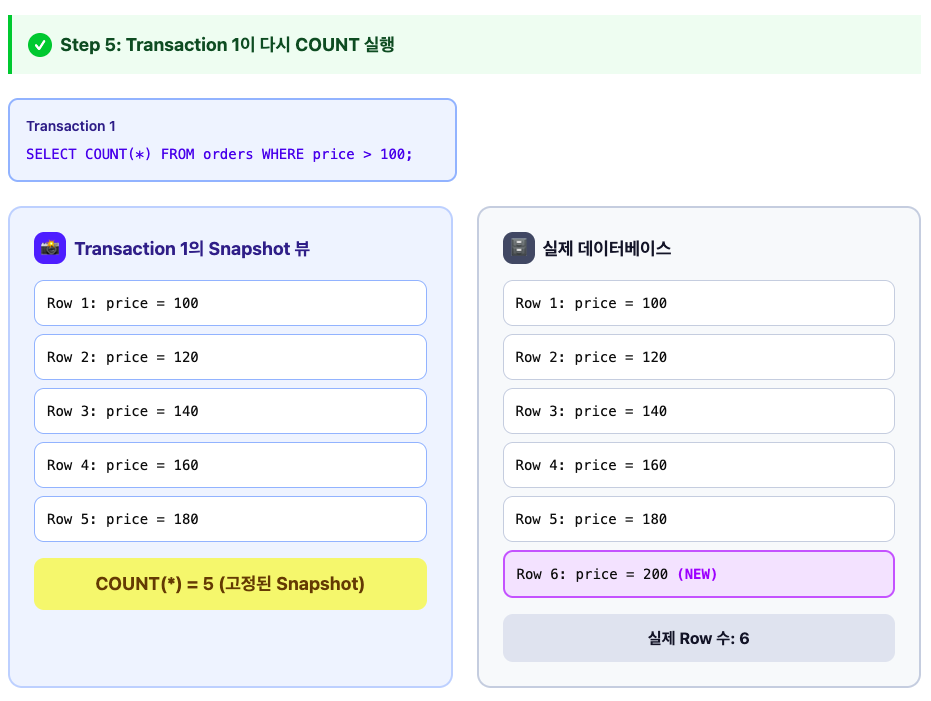
이렇게 되면, PostgreSQL에서는 결과가 여전히 5입니다.
Snapshot이 고정되어 있기 때문입니다.
그래서 PostgreSQL에서는 Phantom Read가 육안으로 확인이 안되는 것입니다.
하지만, write skew 같은 anomaly는 발생합니다.
예를 들어 이해해보겠습니다.
병원 규칙 : 항상 최소 1명의 의사가 근무 중
테이블
| doctor | on_call |
| A | true |
| B | true |

Transaction 1
1) SELECT COUNT(*) WHERE on_call=true → 2
Transaction 2
1) SELECT COUNT(*) WHERE on_call=true → 2
Transaction 1
2) UPDATE doctor SET on_call=false WHERE doctor='A'
Transaction 2
2) UPDATE doctor SET on_call=false WHERE doctor='B'
Transaction 1 & Transaction 2 모두 커밋 → 결과

A = false
B = false
규칙이 깨지게 됩니다.

이건 Repeatable Read에서도 발생 가능한 anomaly입니다.
그래서 이를 막기 위해 PostgreSQL은 SERIALIZABLE = SSI 를 도입했습니다.
반대로 MySQL (Inno DB)는 Repeatable Read에서 Phantom Read 자체를 실제로 막습니다.
이는 Next-Key Lock을 사용하기 때문입니다.
Next-key Lock은 Record Lock + Gap Lock입니다.
UPDATE Stock s
SET s.stockQuantity = s.stockQuantity - :qty
WHERE s.productDetailsId = :detailId
AND s.stockQuantity >= :qty
이 쿼리가 실행되면 stockQuantity가 qty 이상이고 productDetailsId와 detailId가 같은 경우 다른 트랜잭션이 INSERT하려고 하면 BLOCK 즉 phantom insert 자체를 막습니다.
아래 사진 자료로 자세히 설명하겠습니다.

초기에 위와 같이 3개의 레코드가 존재합니다.

이때, Transaction 1이 위에서 작성한 쿼리문으로 Update를 실행합니다.

이때, 동시에 Transaction 2가 Insert를 시도하면 Insert 자체가 Blocked 됩니다.

Transaction 1이 커밋되고

이후, Lock이 해제되어 Transaction 2가 Insert에 성공하게 됩니다.
2) Serializable = 비관락 기반 동작?
Serializable은 애초에 무조건 트랜잭션이 순차적으로 진행되므로, 비관락을 구현하는 방식과 동일하게 구현되어 있을 것이라고 생각하고 있었습니다. 생각의 흐름은 아래와 같았습니다.
Serializable = 모든 트랜잭션을 순차적으로 실행 → 결국 락을 통해 순서를 강제하는 것 →비관락과 같을 수밖에 없지 않을까?
하지만 위에서 말한 것과 같이 항상 락기반으로 동작하지는 않습니다.
Serializable을 구현하는 방식에는 크게 두 가지가 있습니다.
- Lock 기반 (2PL)
대표적으로 MySQL의 Serializable은 락 기반 방식은 맞습니다.
모든 읽기에도 공유락을 걸어 동시성을 강하게 제한합니다. - Snapshot 기반 (SSI)
PostgreSQL에서는 Serializable을 SSI (Serializable Snapshot Isolation) 방식으로 구현합니다.
이 방식은 트랜잭션 간의 충돌 관계를 분석하여 직렬화 불가능한 상황이 발생하면 트랜잭션을 롤백시키는 방식입니다.
정리해보면 아래와 같습니다.

즉, Serializable이 반드시 락기반은 아닌 것입니다.

3) MySQL의 MVCC ??
격리 수준의 내부 동작을 이해하려다 보니 MySQL의 InnoDB 엔진이 MVCC를 사용한다는 것을 알게 되었습니다.
MVCC 는 Multi-Version Concurrency Control의 약자로, 여러 트랜잭션이 동시에 같은 데이터를 읽고 수정할 수 있는 환경에서 락을 최소화하면서 일관성을 유지하기 위한 동시성 제어 기법입니다.
그렇다면 InnoDB는 어떤 방식으로 이를 구현할까요?
이를 가능하게 하는 핵심이 바로 Undo Log 입니다.
트랜잭션이 어떤 레코드를 수정하면 InnoDB는 기존 값의 이전 버전을 Undo Log에 저장합니다.
이렇게 되면 하나의 레코드는 물리적으로 하나지만, 논리적으로는 여러 개의 버전을 갖게 됩니다.
예를 들어 다음과 같은 업데이트가 발생했다고 가정해 보겠습니다.
Version 3 = 현재 값 → Version 2 → Version 1 (Undo Log)

초기에 위와 같이 Version 1이 있습니다.

Transaction 2가 Update 실행을 하면서, 이전 버전은 Undo Log에 저장됩니다.

이때 Transaction 3이 Version 3으로 Update를 시키게 되며 이전 버전들은 Undo Log에 남게 됩니다.
이때, 각 트랜잭션은 데이터를 읽을 때 자신의 Read View를 기준으로 어떤 버전을 볼 수 있는지 판단합니다.
Read View에는 다음과 같은 정보가 포함됩니다.
- 현재 활성 트랜잭션 목록
- 트랜잭션 ID 범위
- 어떤 버전이 visibility를 가지는지에 대한 기준
SELECT가 실행되면 InnoDB는 아래의 과정을 거칩니다.
- 현재 레코드의 트랜잭션 ID 확인
- Read View와 비교하여 해당 버전이 보이는지 판단
- 보이지 않는다면 Undo Log를 따라 이전 버전으로 이동

즉, 트랜잭션은 Undo Log에 연결된 버전 체인을 따라가면서 자신이 볼 수 있는 버전을 찾는 것입니다.
위의 예시를 그대로 가져와보겠습니다.
Transaction 1이 Read View로 본 버전은 아래와 같습니다.

Transaction 2는 아래와 같이 볼 수 있게 됩니다.

Transaction 3는 아래와 같이 볼 수 있게 됩니다.

이 구조 덕분에 아래의 특징이 생기게 됩니다.
- 읽기 작업은 대부분 락 없이 수행된다.
- 트랜잭션이 시작된 시점의 스냅샷을 기준으로 데이터를 읽는다.
- 동일 트랜잭션에서 같은 데이터를 여러 번 읽어도 항상 같은 값을 보게 된다.
이것이 바로 InnoDB가 Repeatable Read를 구현하는 핵심 메커니즘 MVCC입니다.
4) Undo 영역이란 무엇일까??
데이터베이스는 기본적으로 ACID 특성을 보장해야 합니다.
그 중에서도 특히 다음 두 가지 특성이 로그와 깊은 관련이 있습니다.
Atomicity : 트랜잭션이 전부 수행되거나 전혀 수행되지 않아야 한다.
Durability : 커밋된 데이터는 시스템 장애가 발생해도 유지되어야 한다.
이 두가지를 보장하기 위해 데이터베이스는 여러 종류의 로그를 사용합니다.
대표적으로는 Redo Log와 Undo Log가 있습니다.
Redo Log
Redo Log는 시스템 장애가 발생했을 때 커밋된 데이터를 다시 복구하기 위한 로그입니다.
예를 들어 아래와 같은 상황을 생각해 볼 수 있습니다.
트랜잭션 COMMIT → 디스크 반영 전에 서버 크래시
이 경우 Redo Log를 통해 커밋된 변경 사항을 다시 재적용하여 데이터의 Durability를 보장합니다.
Undo Log
반면 Undo Log는 트랜잭션 롤백을 위해 이전 데이터 상태를 저장하는 로그입니다.
트랜잭션이 데이터를 수정하면 InnoDB는 다음과 같은 순서로 처리합니다.
- 기존 데이터의 이전 버전을 Undo Log에 기록
- 실제 데이터 페이지에 변경 적용
- 트랜잭션이 롤백될 경우 Undo Log를 이용해 원래 상태로 복구
즉, Undo Log는 다음 두 가지 역할을 합니다.
- 트랜잭션 Rollback 지원 (Atomicity 보장)
- MVCC에서 이전 버전 데이터 제공
그렇다면, Undo Log는 어디에 저장될까?
InnoDB에서는 데이터 변경이 발생하면 먼저 Undo Log Buffer에 기록하고 이후 디스크에 기록됩니다.
위에서 들었던 balance를 UPDATE하는 예시를 가져와보겠습니다.
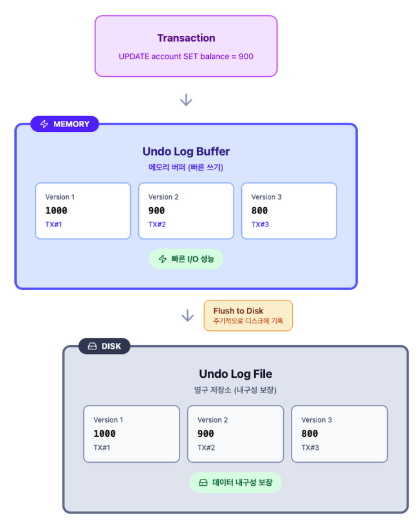
위와 같이 Memory에 저장을 시키며 이후 Disk로 Flush 시키게 됩니다.
이렇게 메모리 버퍼를 먼저 사용하는 이유는 Disk I/O 비용을 줄이기 위해서입니다.
실제로 Undo 정보를 확인해보면
아래와 같은 쿼리문을 통해 InnoDB 내부 상태와 트랜잭션 정보를 확인할 수 있습니다.
//InnoDB 내부 상태와 트랜잭션 정보 확인
SHOW ENGINE INNODB STATUS;
//현재 실행 중인 트랜잭션 확인
SELECT * FROM information_schema.innodb_trx;
//Undo 관련 메트릭 확인
SELECT * FROM information_schema.innodb_metrics WHERE name LIKE '%undo%';
아래와 같이 InnoDB 트랜잭션을 확인하게 되면 여러 정보를 얻게 될 수 있습니다.
사진에 있는 정보를 제외하고도 trx_concurrency_tickets, trx_row_locked, trx_is_read_only, trx_autocommit_non_lokin 등등의 정보를 얻을 수 있습니다.

아래와 같이 Undo와 관련된 메트릭을 확인하게 되면 여러 정보를 얻을 수 있습니다.
이외에도 TIME_ELAPSED, TIME_RESET, STATUS, TYPE, COMMENT등등 확인 가능합니다.

5) 오라클은 Repeatable Read를 지원하지 않는다?
대표적인 상용 DB 중 하나인 Oracle Database는 흥미롭게도 Repeatable Read 격리 수준을 지원하지 않습니다.
오라클이 제공하는 주요 격리 수준은 아래 두 가지입니다.
- Read Committed (기본값)
- Serializable
이를 보면 의문이 생깁니다.
Repeatable Read가 없다면 Non-Repeatable Read가 발생하는 것 아닌가?
실제로 Read Committed에서는 동일 트랜잭션에서 같은 데이터를 다시 읽을 때 다른 값이 반환될 수 잇습니다.
하지만 오라클 역시 MVCC 기반의 읽기 일관성을 사용하기 때문에 이를 방지할 수 있었습니다.
Oracle의 선택 : Consistent Read
오라클에서는 SELECT가 실행될 때 쿼리 시작 시점의 스냅샷을 기준으로 데이터를 읽습니다.
즉 내부적으로 MySQL과 유사하게 Undo 영역을 따라가며 쿼리 시작 시점의 버전을 찾아 읽습니다.
다만 트랜잭션 전체가 아니라 쿼리 단위로 스냅샷이 유지되기 때문에 동일 트랜잭션에서 여러 번 조회하면 값이 달라질 수 있습니다.
반면 MySQL은 트랜잭션 단위로 스냅샷을 유지시켜 동일 트랜잭션에서 여러 번 조회해도 결과 값이 같은 것입니다.
6) MySQL에서도 Read Commited를 쓰면 안될까?
대부분의 DBMS는 기본 격리 수준으로 Read Committed를 사용합니다.
대표적으로 PostgreSQL과 Oracle DB가 기본으로 Read Committed를 사용합니다.
하지만, MySQL (InnoDB)는 기본 격리 수준으로 Repeatable Read를 사용합니다.
그렇다고 Read Committed를 사용하면 안되는 것은 아닙니다.
오히려 특정 상황에서는 Read Committed가 더 좋은 선택이 될 수 있다고 생각하게 되었습니다.
- 락 경합이 심한 서비스
Repeatable Read에서는 특정 조건의 쿼리에서 Gap Lock이 발생할 수 있습니다.
예를 들어 아래와 같은 범위 조회가 있다고 가정해보겠습니다.
SELECT * FROM orders
WHERE price > 100
FOR UPDATE;
InnoDB에서는 이 쿼리가 실행되면 Next-Key Lock이 발생하며 조건에 해당하는 범위 전체가 잠길 수 있습니다.
이 경우 다른 트랜잭션이 해당 범위에 데이터를 삽입하려 하면 락 대기가 발생합니다.
반면 Read Committed에서는 Gap Lock이 대부분 발생하지 않기 때문에 이런 락 경합을 줄일 수 있습니다.
허나, 이는 Phantom Read를 발생시키므로 도메인에 맞게 사용하는 것이 중요할 것 같습니다.
- 조회 중심의 서비스
예를 들어 검색 서비스, 통계 조회, 피드 조회와 같은 서비스에서는 데이터 정합성보다 동시 처리 성능이 더 중요할 수 있습니다.
이 경우 Read Committed를 사용하면 락 대기 시간이 줄어들고 트랜잭션 간 간섭이 줄어 전체 처리량이 증가할 수 있습니다.
7) Ucommited Read는 왜 있는 걸까?
Read Uncommitted는 트랜잭션 격리 수준 중 가장 낮은 단계입니다.
이 격리 수준에서는 아직 커밋되지 않은 데이터를 읽을 수 있으며, 그 결과 Dirty Read가 발생할 수 있습니다.
예를 들어 한 트랜잭션이 데이터를 수정한 뒤 아직 커밋하지 않은 상태에서 다른 트랜잭션이 그 값을 읽는 상황이 발생할 수 있습니다.
아래의 예시를 통해 자세히 살펴보겠습니다.

Transaction 1
1) UPDATE account SET balance = 1000 WHERE id = 1;
Transaction 1이 Update하였으며, 아직 커밋되기 이전입니다.
Transaction 2
1) SELECT balance FROM account WHERE id = 1;
-- 1000 읽음 (Dirty Read)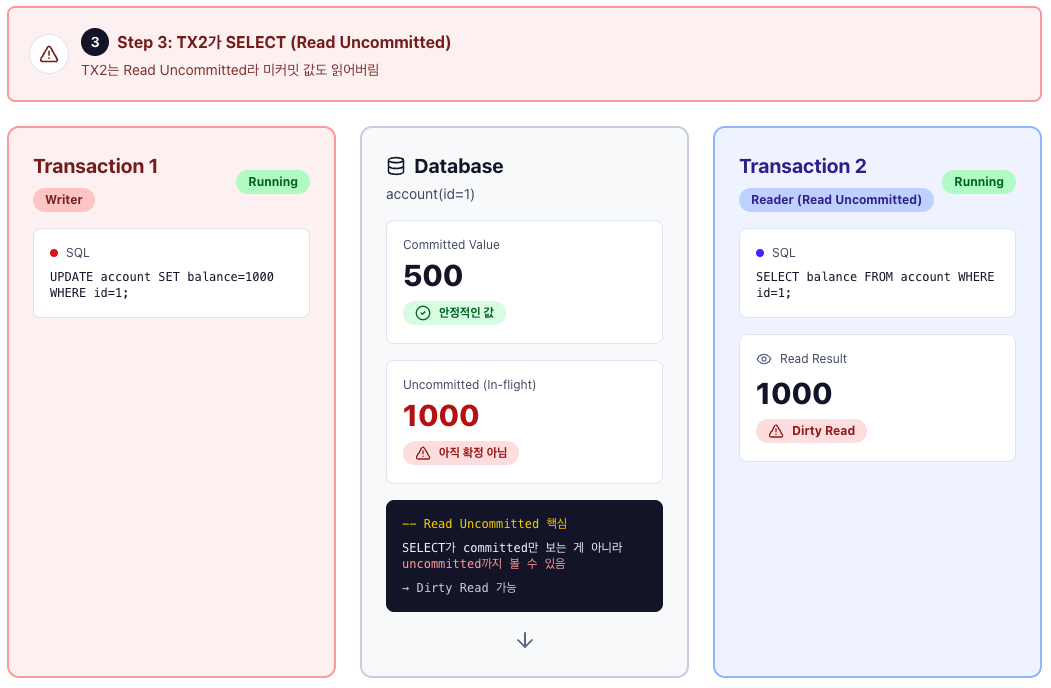
위와 같이 Transaction 2는 1000이라는 값을 Read하게 됩니다.
Transaction 1
2) ROLLBACK
Transaction 1이 Rollback을 하게 되면 결과적으로 Transaction 2는 실제로 존재하지 않는 데이터를 읽게 됩니다.
이에따라 아래와 같은 결과가 나타나게 됩니다.

이런 문제 때문에 대부분의 시스템에서는 데이터 정합성이 중요하며 실제로 Read Uncommitted는 거의 사용되지 않습니다.
심지어 Oracle Database는 이 격리 수준을 지원하지 않습니다.
그래도 사용할 수 있는 경우를 생각해보면 정합성이 크게 중요하지 않은 일부 시스템에서는 Read Uncommitted가 활용될 가능성이 있습니다.
예를 들면 아래와 같은 경우입니다.

예를 들어 현재 접속자 수나 대략적인 트래픽 흐름을 확인하는 상황에서는 일시적으로 부정확한 값이 발생하더라도 큰 문제가 되지 않을 수 있습니다.
👀 결론
이번 글을 정리하면서 트랜잭션 격리 수준에 대해 생각보다 모르는 부분이 많다는 것을 느꼈습니다.
정리를 해보면,
대표적인 예로 주요 DBMS는 다음과 같은 방식으로 격리 수준을 구현합니다.
- MySQL (InnoDB)
→ MVCC + Next-Key Lock을 기반으로 Repeatable Read를 구현하며 Phantom Read를 방지합니다. - PostgreSQL
→ MVCC 기반 Snapshot Isolation을 사용하며 Serializable 격리 수준에서는 SSI를 통해 직렬화 가능성을 보장합니다.
즉, 격리 수준의 이름만 동일할 뿐 실제 내부 구현 방식은 DBMS마다 다르게 동작합니다.
'Study' 카테고리의 다른 글
Contents
소중한 공감 감사합니다