Study
(CS Study) Paging : OS Level 부터 Application Level까지
- -
👀 들어가기 전에
개발을 하다보면 Paging이라는 단어를 여러 곳에서 만나게 됩니다.
- 운영체제의 Virtual memory Paging
- 데이터베이스의 Buffer Pool Paging
- 웹서비스에서 사용하는 Pagination (offset / cursor)
모두 같은 단어를 사용하기에 이전부터 많이 헷갈렸습니다.
큰 뜻에서는 데이터를 일정단위로 나누어 다룬다는 공통점이 있지만, 계층, 목적, 관리 대상, 내부 동작은 생각보다 꽤 다릅니다.
그 중에서도 운영체제의 Paging은 다른 맥락의 Paging을 이해할 때 기준점이 되는 핵심 개념이라고 느꼈습니다. 이번 글에서는 그 중 OS LEVEL의 Paging에 대해서 깊이있게 탐구해보고 Application SW를 개발하는 입장에서 어떤 부분들을 신경써야 하는지, 왜 중요한 개념인 것인지를 짚고 넘어가도록 하겠습니다.
👀 본론
1. 왜 Paging이라는 단어가 여러 곳에서 등장할까?
Paging이라는 단어는 운영체제, 데이터베이스, 웹 서비스까지 다양한 계층에서 반복해서 등장합니다.
이들이 공유하는 공통된 사고방식은 아래와 같습니다.
큰 데이터(?)를 작은 단위로 나누어 관리한다
하지만 여기서 중요한건 무엇을 나누는지와 왜 나누는지가 다르다는 점입니다.
OS Paging은 가상 메모리를 페이지 단위로 나누고 물리 메모리에 매핑시킵니다.
DB Paging은 디스크와 메모리 사이에서 데이터 I/O 단위를 페이지로 관리합니다.
Pagination은 사용자에게 보여줄 데이터를 분할 조회하게 됩니다.
이 글에서는 그 중에서도 가장 근본적인 레이어인 운영체제의 Paging을 설명드리겠습니다.
2. OS Level Paging은 무엇인가?
OS Paging을 한 줄로 정의하면 다음과 같습니다.
가상 주소 공간을 페이지 단위로 나누고, 이를 물리 메모리의 프레임에 매핑하는 메모리 관리 기법
여기서 핵심은 가상 주소와 물리 주소를 분리하는 것입니다.
프로세스는 자신만의 연속된 가상 주소 공간을 사용하지만 실제 물리 메모리인 RAM은 반드시 연속적일 필요가 없습니다.
운영체제는 이 둘을 페이지 단위로 연결하여 프로세스 입장에서는 항상 연속된 메모리를 사용하는 것처럼 보이게 만듭니다.
우선 이를 이해하기 위해서는 메모리 계층 구조와 가상메모리 시스템의 동작 원리를 이해해야 합니다.

흔히 많이 보신 그림일 것이라 생각됩니다.
메모리는 속도, 용량, 가격 등을 기준으로 계층 구조를 이루고 있습니다.
CPU에서 멀리 떨어진 순서부터 가까운 순서까지 나열한 메모리입니다.
CPU에 가까울 수록 가격은 비싸고, 용량은 작아지며, 접근 속도는 빨라집니다.
이처럼 계층적인 구조는 자원의 속도와 용량을 상호 보완하는 역할을 합니다. 빠른 자원(Cache, DRAM)은 적은 양만 사용하고 느리지만 큰 자원(Disk)은 보조적인 역할을 수행하게 하는 것입니다.
그런데 왜 가상메모리가 필요할까??
그럼 가상 메모리는 왜 필요할까요?
예를 들어 설명해보겠습니다.
컴퓨터에 8GB 메인메모리 (DRAM)가 설치되어 있다고 하겠습니다.
OS 커널, 백신, 실행 중인 여러 프로그램과 같은 것들이 이 컴퓨터의 메모리를 다 차지해버리면 결국은 실행해야 할 다른 프로그램을 위한 공간이 부족해지게 됩니다. 이때 등장하는 개념이 바로 가상메모리입니다.
가상메모리란 메모리가 부족할 때, 하드디스크의 일부 공간을 마치 메모리처럼 사용하는 개념입니다.
정확히는 다음과 같습니다.
각 프로세스에게 독립적인 가상 주소 공간을 제공하고,
실제 물리 메모리와 디스크를 함께 활용하여 메모리를 효율적으로 관리하는 시스템
가상메모리는 항상 존재하며, 항상 준비되어있습니다.
윈도우에서 잘 찾아보면 가상메모리의 양을 설정하는 메뉴가 있는데 디폴트로 하드디스크의 일정량을 잡아서 항상 갖고 있고
그 중 사용되는 양은 그때 그때 다릅니다. 그래서 기본적으로 가상메모리는 항상 하드디스크가 쓰고 있는 것입니다.

이때, 하드디스크는 페이지를, 메인메모리는 페이지 프레임을 운영체제는 이 둘을 같은 크기로 나눈 뒤, 필요한 페이지만 메모리로 가져오고 덜 쓰는 페이지만 하드디스크로 보내는 방식으로 관리합니다. 그리고 이 방식이 바로 페이징이 되는 것입니다.
이 전체 구조를 정리하면 아래와 같습니다.
1) 프로세스는 가상 주소 공간을 사용한다.
2) 가상 주소는 페이지 단위로 나뉜다.
3) 각 페이지는 물리 메모리의 프레임에 매핑된다.
4) 일부 페이지는 메모리에 없을 수도 있고, 디스크에 존재한다.
5) 필요할 때 메모리로 가져온다.
이런 관리 방식이 바로 운영체제의 Paging 입니다.
3. 왜 Paging이 필요했는가
사실 여기까지는 전공 수업을 잘 들었다면 배우는 내용입니다.
그럼 왜 하필 페이징이어야 했을까요?
다른 방식으로 관리하는 방법은 없었을까요?
이에 대한 해답을 지금부터 찾아보도록 하겠습니다.
초기의 메모리 관리 방식은 매우 직관적이었습니다.
프로세스 하나가 물리 메모리에서 하나의 연속된 공간이었습니다.
즉, 프로그램이 실행되려면 메모리 안에 끊기지 않은 연속된 공간을 확보해야 했습니다.
그러나!
시간이 지나면서 프로세스들이 생성되고 종료되기를 반복하면 메모리는 아래처럼 조각나기 시작합니다.

겉으로 보면 빈 공간이 꽤 많아 보이지만, 문제는 연속된 공간이 아니라는 점입니다.
결과적으로 총 여유 메모리는 충분한데도 큰 프로세스를 올릴 수가 없게 된 것입니다.
쓸 수 있는 메모리가 있는데도 못쓰는 상황이 발생한 것입니다. 이것이 바로 외부 단편화입니다.
그래서 나온 개념이 Compaction (메모리 재배치) 입니다.
메모리의 빈 공간을 한쪽으로 몰아서 연속된 공간을 만드는 방식입니다.
하지만, 이 방법에는 매우 현실적인 문제가 따라왔습니다.
- 모든 프로세스를 이동시켜야 합니다.
- 실행 중인 프로그램의 주소도 전부 수정되어야만 합니다.
- 메모리 전체를 복사하는 것과 같이 비용이 매우 크게 발생합니다.
결론적으로 굉장히 비효율적인 방식이 되는 것입니다.
그러면 여러분이라면 어떻게 만들었을 것 같나요?
굳이 메모리를 연속으로 써야 할까요?
이 질문이 바로 Paging의 출발점입니다.
Paging은 문제를 사고 방식의 전환으로 바꿔버립니다.
프로세스는 반드시 연속된 메모리를 가져야한다는 편견을 깨버립니다.
프로세스를 더이상 하나의 연속된 덩어리로 취급하지 않고 페이지 단위로 쪼개어 물리메모리의 비어 있는 프레임에 분산 배치합니다.
이로써 연속 메모리에 대한 제약을 제거합니다.
4. Paging의 동작 방식
그럼 이 Paging은 어떻게 동작할까요?
Step 1. CPU는 가상 주소를 만든다.
CPU는 절대 물리 주소를 직접 사용하지 않습니다.
항상 아래 그림 (대학교 강의 PPT)과 같이 페이지번호와 오프셋을 사용합니다.

페이지 번호로 어디있는지를 찾고 이를 토대로 오프셋에서 페이지 안에서의 위치를 찾습니다.
Step 2. 무조건 TLB 부터 확인한다.
우선, TLB를 먼저 확인합니다.

경우 1) TLB Hit
이 경우는 이미 캐시에 존재하는 경우 입니다.
페이지 번호를 통해 프레임 번호를 바로 얻어서 물리 주소를 생성해 메모리에 접근합니다.
경우 2) TLB Miss
캐시에 존재하지 않는 경우 입니다. 이럴 때는 아래의 단계를 따라가게 됩니다.
Step 3. 페이지 테이블 확인
페이지 번호로 페이지 테이블을 조회하게 됩니다.
여기서도 두가지 경우로 나뉘게 됩니다.
경우 1) 페이지 테이블에 존재하는 경우
결국 메모리에 존재한다는 것이고 프레임 번호를 찾고 이를 토대로 TLB를 업데이트합니다.
그 후 물리 주소를 생성하여 메모리에 접근합니다.
경우 2) 페이지 테이블에도 없는 경우
페이지 테이블에도 없는 경우에는 Page Fault가 발생하게 됩니다.
Page Fault란 CPU가 어떤 데이터를 실행하려고 했을 때, 그 데이터가 메인 메모리에 없으면 발생하는 현상입니다.
이 경우 하드디스크에서 해당 페이지를 메모리로 복사해오고 공간이 없다면 기존 데이터를 다시 디스크로 내보내게 됩니다.
그렇기 때문에 페이지 폴트가 자주 발생하게 되면
메모리와 디스크 간 교환이 너무 자주 일어나게 되어 전체 시스템의 속도 자체가 매우 느려집니다.
메모리에 접근하는 것은 ns 단위이지만, 디스크에 접근하는 것은 ms 단위가 되어버립니다.
이후, 페이지 테이블 갱신 후 최종 물리 주소를 변환 완료하게 됩니다
🚨 여기서 잠깐 !!!
Page Fault(페이지 부재)는 메모리 보호의 목적으로도 사용됩니다.
허락 받지 않은 프로그램이 접근하면 일부러 Page Fault를 일으켜 차단 시켜 버리기도 합니다.
그럼 계속해서 Page Fault가 발생한다면 어떤 문제가 발생할까요?
계속해서 Page Fault가 발생하게 되면 CPU가 처리하기 보다는 계속 디스크와 메모리만 교환하는 상황이 발생될 수 있습니다.
이를 Thrashing이라고 합니다.
어떻게 해결할 수 있을까요?
메모리 자체의 문제이다 보니 메모리 용량을 늘리는 것이 가장 확실한 해결책입니다.
그리고 프로그램을 사용하고 있는 사용자의 입장에서는 사용하지 않는 앱이나 백그라운드 프로그램을 종료시켜 어떻게든 정해진 자원 내에서 메모리 공간을 확보하는 것이 중요할 것 같습니다.
또는 오래된 프로세스가 잡고 있는 메모리를 회수해주고 운영체제가 떠돌고 있는 페이지를 정리해주는 작업을 수행하는 것도 필요할 것 같습니다.
그래서 이제 다시 돌아와 TLB를 이용한 물리 주소 변환 과정을 다시 한 번 정리해보겠습니다.
1) 우선, CPU가 발생한 가상 주소 형식을 토대로 TLB를 찾습니다.
2) 만약 TLB에서 적중한다면 그대로 반환해서 물리주소로 계산하여 반환합니다.
3) 만약 TLB에서 실패한다면, 페이지 테이블을 찾습니다.
3-1) 해당 페이지 테이블에서 존재 여부를 확인합니다.
3-2) 페이지 테이블에 존재한다면, TLB를 갱신하고, 물리 주소로 변환시킵니다.
3-3) 페이지 테이블에 존재하지 않는다면, 즉 Page Fault가 발생한다면, 하드 디스크에서 페이지를 찾아 페이지 테이블을 갱신 시킵니다.
이 때, 만약 공간이 없다면 기존 페이지를 내리고, 찾던 페이지로 페이지 테이블을 갱신 시킵니다.
4) 결론적으로 페이지테이블에서 TLB를 갱신시켜서 이를 물리주소로 계산하여 반환합니다.
TLB까지 가야만 할까?
정답부터 말하면 아닙니다. 지금까지의 과정을 다시 한 번 짚어보겠습니다.

앞서 살펴본 Paging에서는 CPU가 생성한 가상주소를 TLB를 통해 물리주소로 변환한 뒤,
해당 물리주소를 기반으로 캐시와 메모리에 접근하게 됩니다.
하지만 위 그림과 같이 가상 주소 캐시를 사용하는 경우,
주소 변환 이전에 먼저 캐시를 확인하는 구조를 갖습니다.
즉, CPU가 생성한 가상주소가 가상주소 캐시에 존재한다면, TLB를 통한 주소 변환 과정 자체를 생략하고 바로 데이터를 사용할 수 있습니다. 반면, 물리캐시는 물리주소를 기준으로 동작하기 때문에 캐시에 접근하기 위해 반드시 TLB를 통해 주소 변환 과정을 거치게 됩니다.
이로 인해 가상주소 캐시는 주소 변환 비용을 줄여 더 빠른 접근이 가능하지만, 동일한 가상주소가 서로 다른 물리주소를 가질 수 있는 aliasing문제를 유발할 수 있습니다.
그렇다면 위 그림에서 MMU는 무엇일까요?
실제 변환(가상주소 → 물리주소)을 빠르게 도와주는 하드웨어 요소가 MMU (Memory Management Unit)입니다.
OS가 전반적인 관리를 하고, MMU가 속도를 높여주는 보조 역할을 합니다.
🚨잠깐!!!
그래서 메모리 용량이 중요한 이유?
사실 메인메모리 (DRAM)을 넉넉하게 달아두면
- Page Fault 발생 가능성은 낮아지고
- 디스크와의 교환 즉, 페이징 발생도 낮아지고
- 프로그램의 실행 속도도 올라갑니다.
예를 들면 8GB의 메모리 컴퓨터는 페이징이 자주 발생할 수 있습니다.
하지만, 16GB 이상의 메모리 컴퓨터는 대부분의 작업이 메모리 내에서 해결 가능합니다.
그렇다보니 램이 클수록 체감 성능이 좋아지는 것입니다.
🚨잠깐!!!
그렇다면 맥북은 같은 메모리 용량인데도 왜 더 빠르게 느껴질까?
mac OS는 커널 자체가 가볍고 시스템이 자원을 효율적으로 관리합니다.
같은 메모리 용량이더라도 윈도우보다 더 여유롭게 느껴지는 이유이기도 합니다.
❓Swapping 이라는 것도 있던데요?
Swapping은 리눅스와 유닉스 계열에서 사용되는 개념입니다.
메모리에서 사용하지 않는 데이터를 디스크로 내려보내는 동작을 의미합니다.
Paging은 윈도우에서는 Swapping까지 포함한 포괄적인 개념으로 사용합니다.
→ .pagefile.sys가 하드디스크에 생성되어 관리되며
→ 리눅스에선 .swap파일이나 swap공간이 생성됩니다.
Paging과 Swapping 둘 다 메모리가 부족할 때를 위한 운영체제의 전략인 것입니다.
5. OS Level Paging의 장점과 비용
우선, Paging의 장점부터 살펴보겠습니다.
1) 외부 단편화 문제의 해결
기존 메모리 관리 방식에서는 프로세스를 연속된 공간에 할당해야만 했습니다.
이로 인해 메모리가 조각나면, 총 여유 공간이 충분함에도 불구하고 큰 프로세스를 할당할 수 없는 문제가 발생했습니다.
Paging은 메모리를 페이지 단위로 분할하고 이를 물리 메모리의 임의 위치에 매핑합니다.
즉, 더 이상 연속된 공간을 요구하지 않게 됩니다.
근본적으로 외부 단편화 문제가 해결되는 것입니다.
2) 메모리 활용 효율 증가
Paging에서는 전체 프로세스를 한 번에 올리는 것이 아니라, 필요한 페이지 단위로 메모리에 적재합니다.
이는 곧 Demand Paging으로 이어지며,
초기 로딩 시 모든 데이터를 메모리에 올릴 필요가 없어지고 실제로 사용하는 데이터만 적재하게 됩니다.
결과적으로 초기 실행 속도가 개선되며 불필요한 메모리 사용이 감소합니다.
3) 프로세스 간 메모리 보호
Paging은 프로세스간 격리를 보장하는 핵심 메커니즘이기도 합니다.
각 프로세스는 독립적인 가상 주소 공간을 가지며, 운영체제는 페이지 단위로 접근 권한 (Read / Write / Execute)을 제어합니다.
예를 들어,커널 영역의 메모리는 사용자 프로그램이 접근할 수 없도록 제한합니다.
사용자가 실수로 커널 영역 주소를 건드렸을 때 발생할 수 있는 시스템이 망가지는 것을 방지하는 것입니다.
4) 가상 메모리를 통한 확장성 확보
Paging의 가장 중요한 장점 중 하나는 가상 메모리를 가능하게 한다는 점입니다.
프로그램 전체를 물리 메모리에 올릴 필요 없이 일부는 디스크에 유지한 채 필요한 순간에만 메모리로 가져옵니다.
결국 Paging은 디스크를 보조 메모리로 활용하여 논리적으로 확장된 메모리 공간을 제공하는 구조인 것입니다.
이제 Paging의 비용을 알아보겠습니다.
앞서 Paging은 메모리 효율과 확장성을 제공한다고는 했지만 그 대가로 추가적인 Overhead가 발생합니다.
1) TLB Miss 비용
Paging 환경에서는 메모리에 접근하기 위해 반드시 주소 변환 과정을 거쳐야만 합니다.
이때 TLB Hit가 발생한다면 바로 물리주소 반환이 가능하지만, TLB Miss가 발생하게 된다면 페이지 테이블을 결국 메모리에서 조회해야합니다.
2) Page Fault 비용
앞서 말한 Page Fault에 따른 비용이 발생하게 됩니다.
Page Fault가 발생하면 커널이 개입하여 해당 페이지를 메모리에 적재합니다.
이 과정에서 디스크 I/O가 필요한 경우, 현재 프로세스는 Block 상태로 전환되고
다른 프로세스가 실행되며 Context Switch가 발생됩니다. 이 또한 매우 큰 비용입니다.
다시 찾은 것을 메모리에 적재하고 페이지 테이블을 업데이트하며 다시 실행하게 됩니다.
디스크를 치게 되기 때문에 결론적으로 큰 비용이 발생하게 되는 것입니다.
6. Application 개발자는 왜 알아야 하는가
Paging은 OS 내부 구현처럼 보이지만 실제 서비스 개발에서도 성능에 직접적인 영향을 미치는 요소입니다.
개발자는 흔히 시간복잡도(Big-O)를 기준으로 코드의 효율을 판단합니다.
물론 이는 중요합니다. 하지만 Big-O가 같더라도 어떤 코드는 훨씬 느리게 동작하는 경우가 자주 발생합니다.
그 차이를 만드는 대표적인 원인 중 하나가 바로 메모리 접근 패턴입니다.
즉, 개발자가 코드를 어떻게 작성하느냐에 따라 Page Fault / TLB miss / Cache miss 발생 빈도가 달라지게 됩니다.
메모리 접근은 생각보다 훨씬 비싸질 수 있다.
CPU가 어떤 데이터를 읽거나 쓸 때, 실제로는 단순히 메모리 한 번 접근으로 끝나지 않습니다.
가상 메모리 시스템에서는 먼저 가상 주소를 물리 주소로 변환해야 하고 그 과정에서 TLB를 조회합니다.
TLB에 정보가 없다면 페이지 테이블을 따라가는 추가 작업이 발생합니다.
그 뒤에도 원하는 데이터가 캐시에 없다면 하위 캐시나 DRAM까지 내려가게 됩니다.
문제는 여기서 끝나지 않습니다.
만약 해당 페이지가 현재 메모리에 존재하지 않는다면 Page Fault가 발생하고 운영체제가 개입해 페이지를 복구하거나 심한 경우 디스크에서 직접 불러와야 합니다. 즉, 개발자가 작성한 한 줄의 코드도 내부적으로는 아래와 같은 경로를 탈 수 있습니다.
- TLB hit → 캐시 hit → 매우 빠름
- TLB miss → page table walk → 느려짐
- cahce miss → DRAM 접근 → 더 느려짐
- Page Fault → 디스크 I/O → 압도적으로 느려짐
이 차이는 단순 미세 최적화 수준이 아닙니다.
L1 캐시는 ns단위, DRAM은 수십 ~ 수백 ns 단위, SSD I/O는 µs 단위, HDD는 ms단위까지 벌어질 수 있습니다.
즉 접근 계층이 한 단계만 내려가도 10배에서 100배 이상씩은 커질 수 있습니다.
Big-O가 같아도 더 느린 이유
알고리즘 복잡도는 같은데 왜 성능 차이가 이렇게 크지? 하는 상황은 종종 발생합니다.
그 이유는 대부분 메모리 지역성 차이에서 나옵니다.
대표적인 예시는 다음과 같습니다.
1. 행 우선 접근 vs. 열 우선 접근
2차원 배열이 연속된 메모리에서 row-major 형태로 저장되어 있다고 하면,
행 방향으로 순회하는 코드는 연속된 데이터를 읽기 때문에 캐시 라인과 페이지를 잘 재사용할 수 있습니다.
반면, 열 방향으로 순회하면 stride가 커지면서, 한 번 읽은 캐시 라인을 거의 재사용하지 못하고 계속 새로운 라인과 페이지를 건드리게 됩니다. 결과적으로 cache miss와 TLB miss가 늘어나고 데이터가 충분히 크면 성능 차이는 눈에 띄게 벌어지게 됩니다.
아래 코드를 실행하여 파악해보겠습니다.
import java.util.*;
public class RowColJava {
static long benchRow(int[][] a) {
long sum = 0;
for (int i = 0; i < a.length; i++) {
int[] row = a[i];
for (int j = 0; j < row.length; j++) {
row[j] = 1;
sum += row[j];
}
}
return sum;
}
static long benchCol(int[][] a) {
long sum = 0;
int n = a.length;
for (int j = 0; j < n; j++) {
for (int i = 0; i < n; i++) {
a[i][j] += 1;
sum += a[i][j];
}
}
return sum;
}
public static void main(String[] args) {
int N = (args.length > 0) ? Integer.parseInt(args[0]) : 4096;
int[][] a = new int[N][N];
long t0 = System.nanoTime();
long s1 = benchRow(a);
long t1 = System.nanoTime();
long t2 = System.nanoTime();
long s2 = benchCol(a);
long t3 = System.nanoTime();
System.out.printf("N=%d s=%d row=%.3f ms col=%.3f ms%n",
N, (s1+s2), (t1-t0)/1e6, (t3-t2)/1e6);
}
}
결과는 아래 사진처럼 나오는 것을 확인할 수 있습니다.

확실히 Row로 접근하면 빠르지만, Col으로 접근하면 느린 것을 확인할 수 있습니다.
약 7배가량 차이가 나는 것을 직접 확인해볼 수 있습니다.
2. 포인터 체이싱
LinkedList, Tree, Hash 기반 구조처럼 다음 주소가 이전 로드 결과에 의존하는 자료구조는 연속된 메모리를 순차적으로 읽는 배열 기반 구조보다 훨씬 불리할 수 있습니다.
Open JDK의 ArrayList는 내부 버퍼가 Object[] elementData (연속 참조 배열)로 구현됨이 소스에 명시됩니다.

반면 LinkedList는 Node <E> {item, next, prev} 형태의 노드 체인으로 구현되어 순회 시 next = next.next 식의 포인터 체이싱이 구조적으로 발생합니다. (이전 ArrayList와 LinkedList의 차이 블로그글 참고)
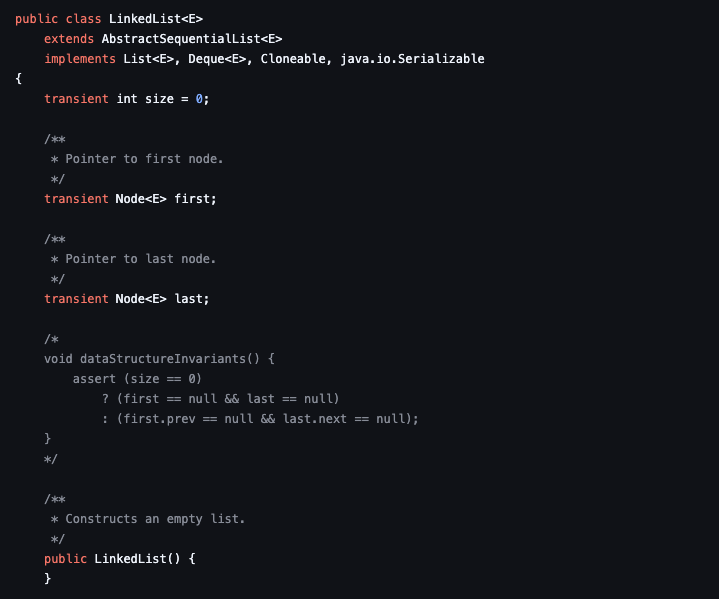
이때 왜 느려지나를 생각해보면 쉽게 생각해볼 수 있습니다.
노드가 흩어져 있으면 캐시 라인 재사용이 약해지고 다음 주소가 이전 로드 결과에 의존하여 Memory Latency가 드러나기 때문입니다. 포인터 체이싱이 불규칙적인 접근을 통한 잦은 cache / TLB miss를 유발한다는 진술은 아래 연구 논문에서 확인 가능합니다.
(참고 자료 : https://users.ece.cmu.edu/~omutlu/pub/in-memory-pointer-chasing-accelerator_iccd16.pdf)

Java에서의 연속은 원시형 배열(int[]) 처럼 in-place 연속 저장과 Object[] 처럼 참조만 연속 저장하는 것이 다릅니다.
그럼에도 LinkedList는 참조 배열 조차 아닌 노드 객체들의 연결이어서 추가 간접이 생기게 되며 (노드 접근 이후 item 접근) 메모리 관점에서의 비용이 커지기 쉬운 것입니다.
3. 전부 한 번에 읽는 코드
데이터를 전부 메모리에 로드하는 방식은 구현은 단순할 수 있지만 실제로는 Working Set을 지나치게 키워 캐시 효율을 떨어뜨리고 메모리 압박을 유발합니다.
실제 코드 레벨에서 큰 데이터를 불러와 (큰 배열을 만들고) 즉시 전부 훑는 행위는
1) Minor Fault를 한꺼번에 만들게 되고
2) RSS를 크게 올려 시스템 메모리에 압박을 키우게 될 수 있습니다.
그렇기 때문에, Chunked Buffer로 스트리밍 처리를 하게 되면 같은 총량을 처리하더라도, 동시에 작업되는 Working Set을 줄여 캐시 / TLB/ Fault 위험을 낮추는 방향으로 동작하게 됩니다.
(참고 자료 : https://people.freebsd.org/~lstewart/articles/cpumemory.pdf ,
https://huichen-cs.github.io/course/CISC3320/19FA/lecture/virtualmemworkset.pdf)
아래 그림을 확인해보면,

맨 왼쪽은 그래프가 부드럽게 증가하다가 특정 지점에서 확 올라가는 부분이 있습니다. 이 부분이 Cache의 용량을 초과한 지점입니다.
가운데 그래프는 같은 Working Set이라도 연속적으로 이루어져 있다면 성능이 좋지만 그에 비해 점프가 이루어진다면 성능이 안좋아 지는 것을 확인해볼 수 있는 그래프 입니다.
맨 오른쪽 그래프는 한 지점에서 엄청나게 급등하는 것을 확인할 수 있습니다.
즉, 캐시 miss가 발생하고 몇십 cycles가 발생하며 TLB miss + 메모리 접근으로 인해 수백 cycles까지 돌고 있는 것을 확인할 수 있습니다.
결론적으로,
- Working Set ≤ L1/L2 Cache → 매우 빠름 (~몇 cycles)
- Working Set > Cache → Cache miss → DRAM 접근 (~100 cycles)
- Working Set > TLB reach → TLB miss + Page walk → 200~400 cycles
가 되는 것입니다.
정리하면, Paging은 운영체제 내부의 추상적인 개념이 아니라
애플리케이션 코드가 실제 하드웨어 위에서 어떤 비용을 발생시키는지 이해하기 위한 핵심 배경지식입니다.
우리가 짜는 코드는 결국 캐시 라인과 페이지를 어떤 순서로 밟고 지나갈지 결정하는 명령 집합이기도 합니다.
그래서 좋은 개발자는 알고리즘만 보는 것이 아니라,
그 알고리즘이 메모리 위에서 어떤 접근 패턴을 만들고 있는지까지 함께 생각해야 하는 것입니다.
👀 마무리하며
Paging은 운영체제 내부의 개념이지만, 실제 서비스 성능은 개발자가 어떤 방식으로 데이터를 접근하고 메모리를 사용하는지에 따라 결정됩니다. 따라서 개발자에게 Paging은 코드 수준에서 성능을 생각하게 되는 중요한 기준이 되는 것입니다.
'Study' 카테고리의 다른 글
Contents
소중한 공감 감사합니다