Study
(CS Study) Spring Bean의 생성과 DI 동작 원리 : ApplicationContext.refresh()부터 populateBean()까지
- -
👀 들어가기 전에
개발을 하다 보면 너무도 익숙해서 오히려 제대로 이해하지 못한 채 사용하는 기술들이 있습니다.
저에게 Spring DI와 IoC가 그랬습니다.
분명 매일같이 사용합니다.
@Component, @Service, @Repository, @Autowired, 생성자 주입까지, 프로젝트 안에서 너무나 자연스럽게 사용하고 있습니다. 하지만 문득 이런 생각이 들었습니다.
"그래서 이건 내부적으로 어떻게 구현되어 있을까?"
"객체를 대신 생성하고 주입해준다는 말은 실제로 어떤 코드와 어떤 흐름으로 동작하는 걸까?"
평소에는 프레임워크가 제공하는 편리함 덕분에 별다른 의문 없이 넘어가기 쉽습니다.
하지만 익숙하게 사용한다는 것과 실제 동작 원리를 이해하고 있다는 것은 전혀 다른 이야기입니다.
특히 Spring은 단순히 객체를 만들어 넣어주는 수준을 넘어 어플리케이션 시작 시점에 어떤 클래스를 빈으로 등록할지 판단하고, 빈 생성 순서를 조정하고, 의존 관계를 해석하고, 필요하다면 프록시 객체까지 만들어 끼워넣습니다.
즉, 우리가 흔히 "DI를 받는다"고 표현하는 한 줄 뒤에는 생각보다 훨씬 복잡하고 정교한 컨테이너의 생명주기와 내부 전략이 숨어 있습니다. 이번 글에서는 막연히 "Spring이 알아서 해준다"라고 넘겨왔던 DI와 IoC 컨테이너를 조금 더 내부 구현 관점에서 따라가보려 합니다.
- Spring Container가 객체를 어떤 방식으로 관리하는지
- BeanDefinition, BeanFactory, ApplicationContext는 각각 어떤 역할을 하는지
- 의존성 주입은 실제로 어느 시점에 어떤 방식으로 수행되는지
- 그리고 이 모든 구조가 왜 Spring을 Spring 답게 만드는지
를 코드 흐름 중심으로 깊이 있게 정리해보겠습니다.
👀 본론
1. Spring DI는 어디서 시작될까?
Spring에서 DI와 IoC는 너무 자연스럽게 사용됩니다.
@Service
public class UserService {
private final UserRepository userRepository;
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
}
Spring Boot 어플리케이션을 실행하면, Spring은 UserService 객체를 생성하고 UserRepository를 자동으로 주입합니다.
하지만, 여기서 한 가지 질문이 생깁니다.
이 주입은 정확히 언제, 어디서 일어날까요?
객체 생성 시점일까요? 컨테이너 초기화 시점일까요? Bean 등록 시점일까요?
이 질문에 답하기 위해서 Spring Framework 내부 코드로 들어가보겠습니다.
우선 Spring Framework의 전체 구조를 보면 아래와 같은 모듈들이 존재합니다.

Spring Framework의 전체 구조를 계층형으로 단순화하면 위와 같이 Core → Context → Data/Web → Support 구조로 볼 수 있습니다. 이 중에서 DI와 IoC의 핵심 구현은 spring-beans 모듈에 있습니다.
이제부터 실제로 Spring 코드에서 Bean이 생성되고 의존성이 주입되는 흐름을 실제로 따라가며 보겠습니다.
2. Spring 컨테이너의 시작
우선, Spring 어플리케이션이 시작되면, Spring 컨테이너가 시작됩니다.
아래 ApplicationContext.refresh() 코드 부터 시작해보도록 하겠습니다.
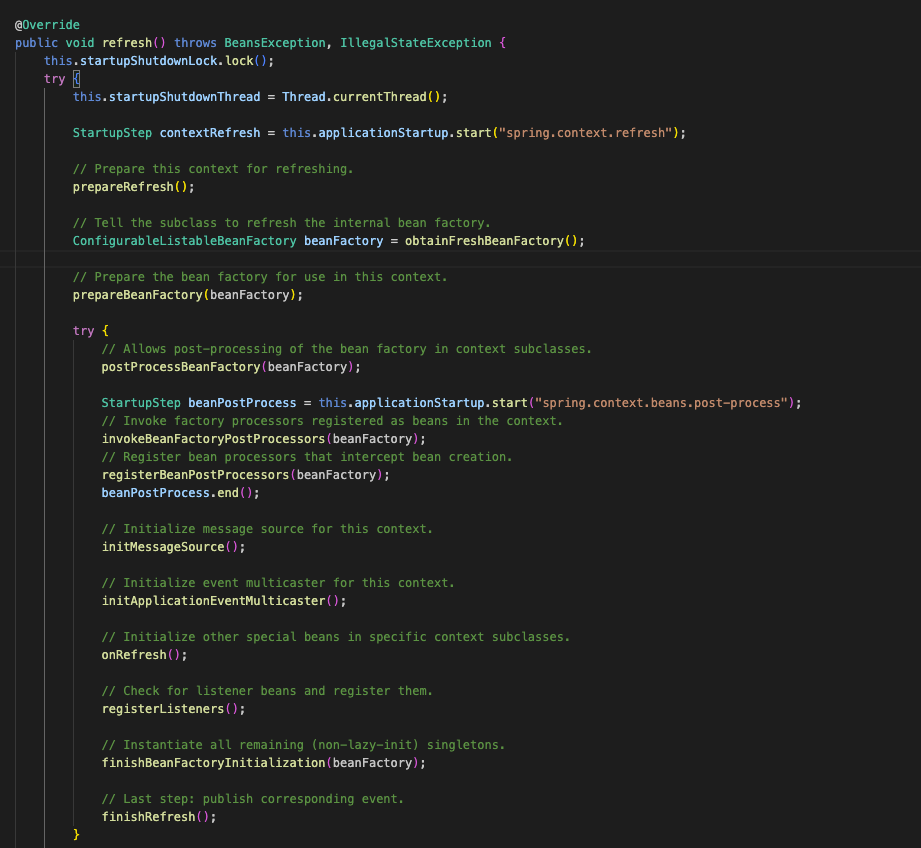
Spring은 시작되는 순간, 위 코드의
prepareRefresh()
protected void prepareRefresh() {
// Switch to active.
this.startupDate = System.currentTimeMillis();
this.closed.set(false);
this.active.set(true);
if (logger.isDebugEnabled()) {
if (logger.isTraceEnabled()) {
logger.trace("Refreshing " + this);
}
else {
logger.debug("Refreshing " + getDisplayName());
}
}
// Initialize any placeholder property sources in the context environment.
initPropertySources();
// Validate that all properties marked as required are resolvable:
// see ConfigurablePropertyResolver#setRequiredProperties
getEnvironment().validateRequiredProperties();
// Store pre-refresh ApplicationListeners...
if (this.earlyApplicationListeners == null) {
this.earlyApplicationListeners = new LinkedHashSet<>(this.applicationListeners);
}
else {
// Reset local application listeners to pre-refresh state.
this.applicationListeners.clear();
this.applicationListeners.addAll(this.earlyApplicationListeners);
}
// Allow for the collection of early ApplicationEvents,
// to be published once the multicaster is available...
this.earlyApplicationEvents = new LinkedHashSet<>();
}
를 통해 먼저 컨테이너 상태를 초기화하고 환경을 검증하게 됩니다.
위 코드는 실제 prepareRefresh 코드를 그대로 붙여온 것입니다.
SpringApplication.run(Application.class);
가 실행되면, 위 코드의 startupDate에 ApplicationContext가 언제 시작되었는지를 기록합니다.
이후, closed의 상태를 false로 표시하고 active 상태를 true로 바꿉니다.
컨테이너의 refresh 로그를 출력합니다. (로그 레벨에 따라 출력 방식이 달라지게 됩니다.)
또한 Property Source를 initPropertySources(); 로 초기화합니다.
아마 여기서 생기는 의문이 있을 수 있는데 이에 대해서는 아래에 다루도록 하겠습니다.
넘어가서, prepareRefresh()에 보면 재밌는 코드가 하나 있습니다.
this.earlyApplicationEvents = new LinkedHashSet<>();
우선 이 코드의 효용은, earlyApplicationEvents 저장소를 초기화하게 되는데, 이는 refresh() 초반부처럼 아직 준비되지 않은 시점에 발생한 이벤트를 임시로 보관하기 위해서입니다. 그렇다면 왜 LinkedHashSet 자료구조여야만 했을까요?
다음 두가지 이유로 생각되어집니다.
- 중복 이벤트 저장 방지
- 발생 순서 유지
LinkedHashSet 자료구조는 발생 순서를 유지해주며, 중복 이벤트 저장 자체를 방지해줍니다.
이제 prepareRefresh()가 끝나게 되면, Spring은 아래 코드들로 BeanFactroy를 새로 준비하고 이후 BeanFactory를 기반으로 후처리 등록, 리스너 등록, singleton bean 생성까지 진행하게 됩니다. 자세하게 코드로 해당 과정을 확인해보겠습니다.

우선, obtainFreshBeanFactory부터 보도록 하겠습니다.

위 코드를 보면, refreshBeanFactory()와 getBeanFactory()를 통해 Bean을 초기화시키는 모습을 확인할 수 있습니다.

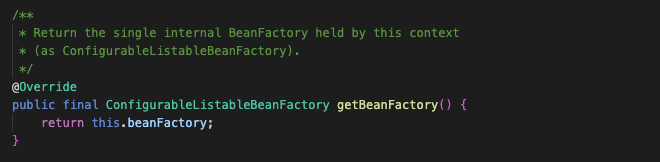
refreshBeanFactory()에서 serializationId를 세팅하고, getBeanFactory()로 내부 beanFactory를 반환하도록 합니다.
즉, obtainFreshBeanFactory()를 통해 이후 Bean 생성에 사용할 BeanFactory 구현체를 준비해서 가져오는 메소드인 것입니다.
다시 돌아가, BeanFactory 구현체를 준비해서 가져오게 되면, prepareBeanFactory를 진행하게 됩니다.

이제 위 prepareBeanFactory 코드를 자세히 살펴보도록 하겠습니다.
prepareBeanFactory()는 obtainFreshBeanFactory()에서 가져온 BeanFactory가 ApplicationContext 환경에서 동작할 수 있도록 기본 규칙과 인프라를 등록하는 단계입니다. 여기서 기본 실행 환경을 설정하고, Aware 인터페이스 기반 콜백처리를 위한 BeanPostProcessor를 등록합니다.
위에서 Aware 인터페이스 기반 처리 준비가 중요하다고 한 이유는 아래 코드 때문입니다.
beanFactory.addBeanPostProcessor(new ApplicationContextAwareProcessor(this));
⭐️ 여기서 나중에 Bean 초기화 직전에 Aware 처리용 BeanPostProcessor를 미리 등록하게 됩니다. (나중에 나오니 기억해두시면 됩니다.) 또한, ApplicationListener 감지용 BeanPostProcessor도 등록하게 되고, 기본 infrastructure singleton을 등록합니다.
다시 refresh 코드로 돌아가겠습니다.
이렇게 BeanFactory까지 준비되면, try 로직 내부로 들어가게 됩니다.
들어가기 전에 지금까지의 흐름을 정리해보겠습니다.
ApplicationContext.refresh()가 호출되면, Spring 컨테이너는 먼저 refresh를 위한 사전 준비 작업을 수행합니다.
이후 obtainFreshBeanFactory()를 통해 사용할 BeanFactory를 새롭게 준비하고, prepareBeanFactory() 단계에서 해당 BeanFactory가 ApplicationContext 환경에서 동작할 수 있도록 기본 설정을 적용합니다.
이 과정에서는 Bean 생성에 필요한 기본 실행 환경을 세팅하고, 이후 Bean 초기화 시점에 동작할 BeanPostProcessor들을 등록합니다.
아직 이 시점에서는 일반 Bean들이 본격적으로 생성된 것은 아니며, 컨테이너가 Bean 생성과 초기화 과정을 수행할 수 있도록 기반을 갖추는 단계입니다.
(추가) Property Source를 initPropertySources(); 로 초기화합니다?
이 코드를 보면 자연스럽게 의문이 생깁니다.
여기서 application.yml 같은 설정 파일을 읽어오는 걸까?
결론부터 말하면 그렇지 않습니다.
SpringBoot에서 application.yml과 같은 설정 파일이 ApplicationContext가 refresh 되기 훨씬 이전 단계에서 이미 Environment에 로드됩니다.
(추가) Aware용? ApplicationListener용? BeanPostProcessor??
Aware용 BeanPostProessor라고 말씀을 드렸는데, 이건 과연 뭘까요?
ApplicationContextAwareProcessor같은 것입니다.
Bean이 아래 인터페이스들을 구현하게 되는데,
- EnvironmentAware
- ResourceLoaderAware
- ApplicationContextAware 등..
Spring이 어떤 Bean이 컨테이너 객체를 알아야 하는 것인지를 알고 setter를 호출해줍니다.
즉, 컨테이너 관련 객체를 Bean에 주입하는 콜백 처리용 후처리기인 것입니다.
그렇다면, ApplicationListener용 BeanPostProcessor는 무엇일까요?
Bean이 ApplicationListenr인지를 감지하여 이벤트 리스너로 적절히 등록/취급되도록 돕는 후처리기입니다.
즉, 두 BeanPostProcessor는 역할이 다릅니다.
ApplicationContextAwareProcessor는 Aware 인터페이스 구현 여부를 보고 컨테이너 객체를 주입하게 되고,
ApplicationListenerDetector는 Bean이 이벤트 리스너인지를 감지하게 되는 것입니다.
이어서 가보도록 하겠습니다.
이제 BeanFactory까지 준비가 끝났습니다. try 블록 내부에서 수행하는 핵심 흐름을 간단히 정리해보겠습니다.
우리가 궁금한 지점은 결국 Bean 생성, DI, IoC가 실제로 어디서 일어나는가이므로 여기서는 전체 단계의 큰 흐름을 잡고 이후 Bean 생성 지점으로 내려가겠습니다.
try 블록 내부의 흐름은 아래와 같습니다.
- postProcessBeanFactory(beanFactory)
- 하위 ApplicationContext 구현체가 BeanFactory를 추가로 가공할 수 있도록 확장 포인트를 제공합니다. - invokeBeanFactoryPostProcessors(beanFactory)
- Bean 정의 자체를 후처리하는 BeanFactoryPostProcessor 들을 실행합니다. - registerBeanPostProcessors(beanFactory)
- 이후 Bean 생성 과정에 개입할 BeanPostProcessor들을 등록합니다. - initMessageSource(), initApplicationEventMulticaster(), onRefresh(), registerListeners()
- 메시지 처리, 이벤트 전파, 리스너 등록 등 컨테이너 부가 기능들을 초기화합니다. - finishBeanFactoryInitialization(beanFactory)
- 남아 있는 non-lazy singleton Bean들을 실제로 생성합니다.
이 부분이 저희가 보고자 하는 Bean 생성, DI, IoC의 핵심 진입점입니다. - finishRefresh()
- 최종 refresh 완료 처리와 이벤트 발행을 수행합니다.
즉, 여기서 눈여겨봐야할 지점은 finishBeanFactoryInitialization입니다.
3. Bean의 실제 생성 (finishBeanFactoryInitialization)
이제 finishBeanFactoryInitialization 부분 로직을 조금 더 깊게 파보도록 하겠습니다.

Bean의 실제 생성에서 finishBeanFactoryInitialization()가 non-lazy singleton Bean을 실제로 생성하는 진입점입니다 .
여기서 호출되는 preInstantiateSingleTons() (빨간 밑줄)는 DefaultListableBeanFactory에 구현되어 있으며, Bean Definition 이름 목록을 순회하면서 singleton Bean들을 실제로 초기화합니다.
아래 코드를 보고 설명드리겠습니다.

List<String> bean Names = new ArrayList<>(this.beanDefinitionNames);
에서 현재 등록된 BeanDefinition 이름 목록을 복사합니다. 순회 중에 새로운 빈 정의가 추가될 수 있기에 원본을 직접 들고 옮기지 않는 방법을 적용한 것입니다.
이후,
this.preInstantiationThread.set(PreInstantiation.MAIN);
에서 지금이 "사전 singleton 생성 단계"라는 컨텍스트를 스레드 로컬에 기록합니다.
풀어서 설명하면, 지금 이 스레드는 preInstantiateSingletons() 실행 중이다라는 표식을 남기게 되는 것입니다.
여기서 preInstantiationThread는 ThreadLocal이라서, 전역 변수처럼 모두가 공유하는게 아니라 현재 스레드별로 따로 저장되는 값입니다. 일반적인 getBean()으로의 호출인지, 아니면 컨테이너 시작 과정의 singleton 사전 생성 단계인지에 대한 구분을 해주는 것입니다.
(잠깐) ThreadLocal??
위에서 preInstantiationThread가 ThreadLocal이라고 하였습니다. 이 ThreadLocal이 무엇을 의미하는지, 어떻게 알 수 있었는지를 코드를 통해 이어서 설명해가보도록 하겠습니다. 우선 ThreadLocal의 정의부터 알아보겠습니다. ThreadLocal은 자바에서 제공하는 Thread safe한 기술로 멀티 스레드 환경에서 각각의 스레드에게 별도의 저장공간을 할당하여 별도의 상태를 갖을 수 있게끔 도와주는 것입니다.

위 코드를 보면, NamedThreadLocal은 Spring의 디버깅 편의를 위해 이름 붙여둔 ThreadLocal의 구현체입니다.
실제 NamedThreadLoacal.java 클래스의 코드를 확인해보도록 하겠습니다.
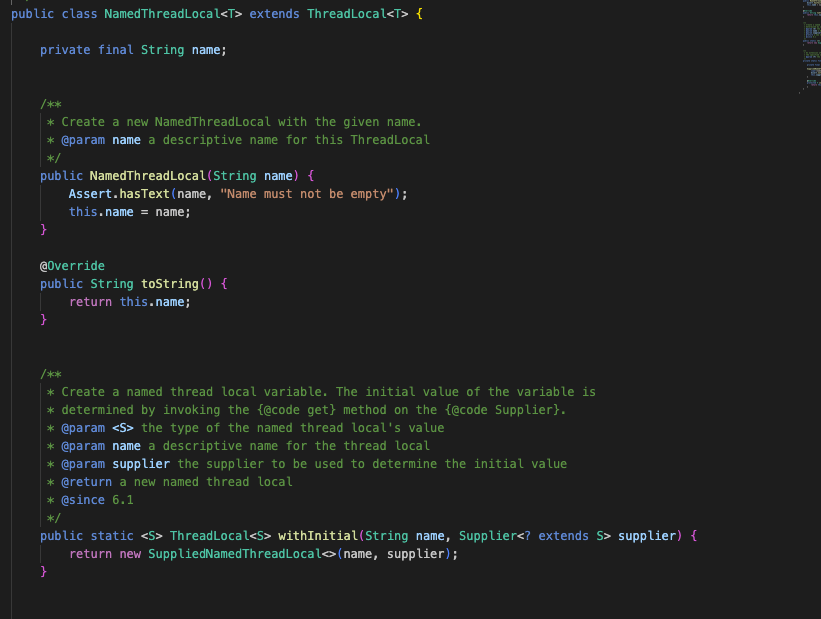
NamedThreadLocal은 ThreadLocal을 상속받고 있는 점을 확인할 수 있습니다. 여기에 name필드를 두어 Name에 따라 구분을 할 수 있도록 만들었습니다.
왜 ThreadLocal이어야 했을까요?
조금만 생각해보면 이유를 짐작해볼 수 있습니다.
Spring 컨테이너는 Bean을 생성하는 과정에서 단순히 한 번의 직선 흐름만 수행하지 않습니다.
특히 컨테이너 초기화 시점에는 여러 Bean이 연쇄적으로 생성되고, 그 과정에서 다른 Bean이 연쇄적으로 생성되고, 그 과정에서 다른 Bean을 조회하거나 초기화하는 흐름이 계속해서 중첩될 수 있습니다. 이때, Spring입장에서는 현재의 Bean 생성 요청이 일반적인 런타임시 나오는 getBean() 호출인지, preInstantiateSingletons()를 통한 컨테이너 bootstrap단계인지 혹은 background initialization 흐름인지를 구분할 필요가 있습니다.
허나, 이런 상태를 공용 필드 하나로 관리해버리면, 여러 스레드가 동시에 Bean 생성에 관여하는 상황에서 서로의 상태가 섞여버릴 수 있게됩니다. 즉, 어떤 스레드는 메인 bootstrap 흐름에서 동작 중인데, 다른 스레드가 값을 덮어버리면 Spring이 현재 값에 대해 잘못 해석해버리게 됩니다. 아래의 그림을 통해 이해할 수 있도록 해보겠습니다.
Thread-A와 Thread-B가 있다고 가정해보겠습니다.

만약, Thread-A가 현재 상태를 BOOTSTRAP 즉, 부팅 중에 발생한 Initiation이라고 상태를 작성했다고 했을 때, Thread-B가 동시에 접근하며 RUNTIME으로 상태를 덮어쓰게 될 경우 상태가 섞이게 됩니다.

이에 ThreadLocal을 사용하여, 상태가 겹치지 않도록 만드는 것입니다.
그래서 Spring은 preInstantiationThread를 ThreadLocal로 두고 현재 실행 중인 각 스레드가 자신의 생성 문맥만 따로 보관하도록 만든 것입니다. 해당 스레드에게만 지금은 singleton 사전 생성의 메인 단계라는 점을 기록하게 되는 것입니다.
다시 돌아가서, 지금까지의 흐름을 정리해보겠습니다.
- ApplicationContext.refresh()가 호출되면 Spring 컨테이너는 우선 refresh를 위한 사전 준비작업을 수행합니다.
- 이후 BeanFactory를 새롭게 준비하고 BeanFactoryPostProcessor, beanPostProcessor, 이벤트 멀티캐스터, 리스너 등록 등 컨테이너가 정상적으로 동작하기 위한 기반을 먼저 갖추게 됩니다.
- 그 다음 finishBeanFactoryInitialization() 단계에 도달하면, Spring은 이제 남아 있는 non-lazy singleton Bean들을 실제로 생성할 준비를 마치게 됩니다.
- 그리고 이 메서드의 마지막에서 preInstantiateSingletons()를 호출하며 BeanDefinition형태로 존재하던 정보들을 실제 Bean 인스턴스로 만들어가기 시작합니다.
그 중, 초기화 메서드가 실행되면서 BeanDefinition 목록을 복사해서 순회하며 beanName들을 List 자료구조에 정리하고,
PreInstantiationThread로 non-lazy Singleton bean들을 초기화하는 로직까지 확인해보았습니다.
이후 PreInstantiateSingletons()의 try-catch 로직을 돌게 됩니다.

핵심 try 구문을 직접 살펴보겠습니다.
List<CompletableFuture<?>> futures = new ArrayList<>();를 통해 비동기적으로 초기화가 수행되는 Bean들의 작업 결과를 저장할 리스트를 준비합니다.
CompletableFuture를 모아두는 것입니다.
그리고 앞에서 복사해둔 BeanDefinition이름 목록을 하나씩 순회하며, 이번에 사전 초기화해야 하는 singleton Bean이 무엇인지를 하나씩 개별적으로 검사하게 되는 것입니다.
RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);위 코드를 통해 현재 beanName에 해당하는 BeanDefinition을 가져옵니다.
부모 정의 상속이나 각종 설정이 병합된 RootBeanDefinition 형태로 반환하여 사용합니다.
즉, 실제 Bean 생성 판단은 병합이 완료된 최종 메타정보를 기준으로 이루어집니다.
이후 아래 조건문으로 실제 생성 대상인지를 판단합니다.
if (!mbd.isAbstract() && mbd.isSingleton()) {여기서 abstract Bean이 아닌가를 확인합니다. 추상 Bean은 그 자체로 실제 인스턴스를 생성할 수 없기 때문입니다.
또한, singleton 범위의 Bean인지를 확인합니다. 즉, preInstantiateSingletons()는 이름 그대로 singletonBean을 미리 생성하는 단계이며 prototype이나 다른 scope Bean을 모두 지금 만드는 것이 아닌 겁니다.
그리고 이 모든 조건들을 통과하게 되면,
CompletableFuture<?> future = preInstantiateSingleton(beanName, mbd);Spring이 해당 Bean에 대한 사전 초기화를 진행합니다. (⭐️ 아래에서 내부적으로 더 깊게 들어가 보겠습니다.)
이후 모든 로직의 수행이 끝나면 아래 Finally 구문을 타게 됩니다.
finally {
this.mainThreadPrefix = null;
this.preInstantiationThread.remove();
}singleton의 사전 초기화 단계가 끝난 뒤, 현재 스레드에 기록해두었던 bootstrap 관련 상태를 정리하는 코드입니다.
즉, preInstantiationThread에 남겨두었던 지금은 singleton의 사전 생성 단계라는 문맥 정보를 제거하여 이후 다른 Bean 생성 흐름에 영향을 주지 않도록 마무리하는 것입니다.
정리하면, Spring이 BeanDefinition 목록을 순회하면서 실제 singleton Bean 생성 작업을 시작하고 필요하다면 비동기 초기화 결과까지 기다린 뒤, 마지막에 bootstrap 상태를 안전하게 정리하는 단계인 것입니다.
결국 여기서는 Spring이 등록된 BeanDefinition 이름들을 순회하면서 추상 Bean이 아니고 singleton 범위인 Bean만 생성 대상으로 선별한 뒤, 해당 Singleton Bean들의 실제 생성과 초기화 과정을 시작하게 됩니다.
4. getBean에서 생성이 시작된다.
Spring이 해당 Bean에 대한 사전 초기화를 진행합니다. (⭐️ 아래에서 내부적으로 더 깊게 들어가 보겠습니다.)라고 했던 부분을 기억하십니까?
CompletableFuture<?> future = preInstantiateSingleton(beanName, mbd);바로 이 코드입니다. 이 코드의 preInstantiateSingleton(beanName,mbd)의 구현체로 내려가보겠습니다.

여기서 getBean(beanName)이 직접 호출되는 점을 확인할 수 있습니다. 이제부터 Spring이 여기 getBean()에서 Bean을 어떤 순서로 생성하고 의존성을 해결하는지 따라가보겠습니다.

여기서 doGetBean()메소드를 호출하게 됩니다.
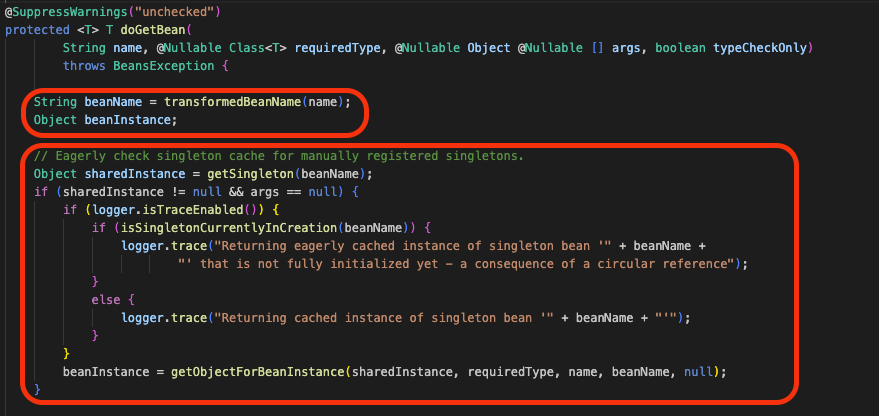
여기서 우선 beanName을 정규화시키고, 이후 캐시에 남아있는 SingletonBean이 있는지 확인하는 작업을 진행하게 됩니다.
우선 sharedInstance = getSingleton(beanName);으로 이미 생성된 singleton 객체가 있으면 sharedInstance에 담기게 됩니다. 그래서 만약 캐시에 이미 객체가 있고, 생성자 인자 같은 특수 요청도 없다면 새로 만들 필요가 없으므로 기존 객체를 그대로 사용하게 됩니다.
이후 아래 코드를 통해 현재 Bean이 실제로 생성 가능한지 확인하는 단계를 거칩니다.
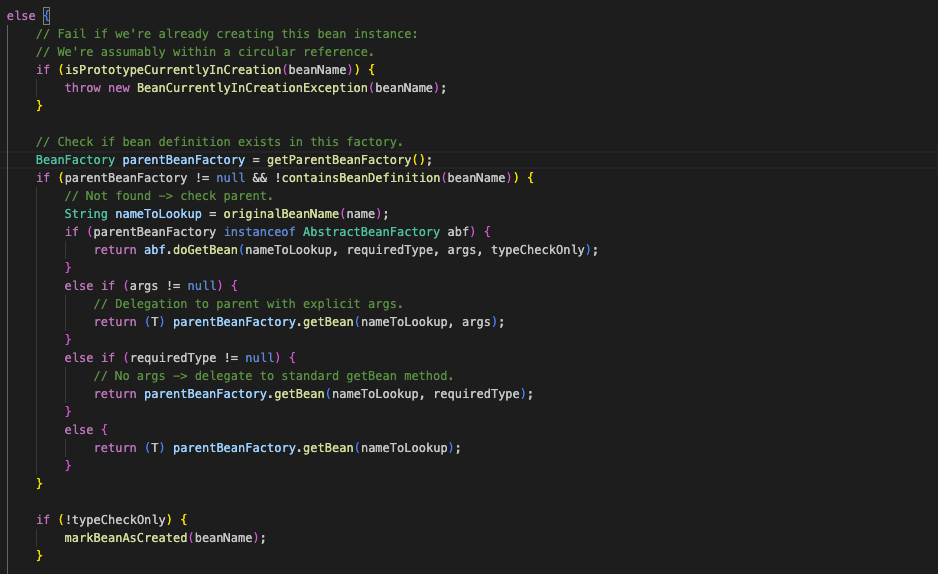
위 코드를 통해 BeanFactory에 해당 Bean의 정의가 없다면 부모 BeanFactory에게 조회와 생성을 위임하는 부분입니다.
즉 Spring 컨테이너는 항상 자기 안에서만 Bean을 찾는 것이 아니라 계층 구조를 따라 상위 컨테이너까지 올라갈 수 있는 것입니다.
(잠깐) 상위 컨테이너란? 어디까지 인거지?
현재 BeanFactory가 부모로 참조하고 있는 컨테이너를 의미합니다.
즉 현재 컨테이너에 Bean이 없으면, Spring은 부모 컨테이너에 같은 Bean이 있는지 다시 조회할 수 있습니다.
일반적인 단일 Spring Boot 어플리케이션에서는 자주 드러나지는 않지만 Spring 자체는 이런 계층형 컨테이너 구조를 지원하는 것을 확인할 수 있습니다.
다시 돌아와서, 현재 Bean을 만들기 전에 선행 의존 Bean을 생성합니다.

singleton 캐시에 Bean이 없다면 Spring은 곧바로 객체를 생성하지 않습니다. 먼저 BeanFactory에 해당 Bean 정의가 존재하는지를 확인하고 없다면 부모 BeanFactory로 조회를 위임합니다. 또한 BeanDefinition에 depends-on 관계가 선언되어있다면, 현재 Bean을 만들기 전에 getBean(dep)를 호출하여 선행 의존 Bean을 먼저 생성합니다. 즉, Spring은 요청된 Bean만 단독으로 생성하는 것이 아니라 필요한 선행 생성 관계까지 먼저 해결하고 다음 단계로 넘어갑니다. 지금까지 doGetBean()은 singleton 캐시 확인, 부모 BeanFactory 위임, depends-on 선행 생성, scope 분기 등을 통해 이 Bean을 실제로 생성해야하는지를 판단해왔습니다.

이제 singleton 캐시에 Bean이 없고 실제 생성이 필요하다고 판단되면, 결국 createBean(beanName, mbd,args)를 호출하며 실제 객체 생성 단계로 내려가게 됩니다.
5. 실제 Bean의 생성 : createBean()
이제부터 doGetBean()이 실제 생성이 필요하다고 판단했을 떄 호출하는 createBean() 내부를 살펴보겠습니다.

createBean()은 Bean 생성의 상위 진입점 역할을 하고 실제 인스턴스 생성과 의존성 주입, 초기화는 그 내부의 doCreateBean()에서 수행됩니다. 이제 doCreateBean()메소드를 자세히 들여다보겠습니다.

우선 자바 객체를 만듭니다. 즉 아직 의존성 주입이 일어나지는 않았으며 순수하게 객체 껍데기를 만드는 단계입니다.
그리고 이 작업은 내부적으로 다시 createBeanInstance()로 위임됩니다.
6. 객체 생성 단계 : createBeanInstance()

여기서(빨간 네모) createBeanInstance는 생성자 주입이 실제로 시작됩니다.
특별한 조건이 없으면, 기본 생성자로 들어가게 됩니다.
(빨간 네모는 autowireConstructor()경로로 내려가 생성자 기반 인스턴스 생성이 진행됩니다.)
여기서 말하는 특별한 조건은 아래와 같습니다.
- BeanPostProcessor가 후보 생성자를 지정한 경우 (ex. Autowired 생성자)
- autowire 모드가 constructor인 경우
- Bean Definition에 생성자 인자가 명시된 경우
- 외부에서 명시적 생성자 인자를 넘긴 경우
인 것입니다. 특별한 조건이 없다면 Spring은 마지막에 기본 생성자를 사용해 객체를 생성하게 됩니다.
(instantiateBean 경로에서 기본적으로 no-args constructor를 사용하는 생성 방식이 사용됩니다.)
7. 만들어진 객체에 의존성을 주입하는 단계 : populateBean()
createBeanInstance()를 통해 객체 자체는 만들어졌습니다.
하지만 이 시점의 객체는 아직 필요한 의존성이 채워지지 않은 상태입니다.
Spring은 다시 doCreateBean()으로 돌아와, 이제 populateBean()을 통해 생성된 객체에 실제 의존성을 주입하게 됩니다.

여기서 populateBean()메소드 흐름을 타게 됩니다.
populateBean()메소드를 살펴보도록 하겠습니다. (길어서 필요한 부분만 추출하였습니다.)
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
...
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {
if (!bp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
return;
}
}
}
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null);
...
if (hasInstantiationAwareBeanPostProcessors()) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {
PropertyValues pvsToUse = bp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
return;
}
pvs = pvsToUse;
}
}
if (pvs != null) {
applyPropertyValues(beanName, mbd, bw, pvs);
}
}
populateBean()은 이미 생성된 객체에 대해 property값과 의존성을 채워넣는 단계입니다.
다만 Spring은 곧바로 값을 주지 않고 먼저 InstantiationAwareBeanPostProcessor들에게 개입 기회를 제공합니다.
먼저 postProcessAfterInstantiation()를 통해 이후 프로퍼티 주입을 진행할지에 대한 여부를 확인하고
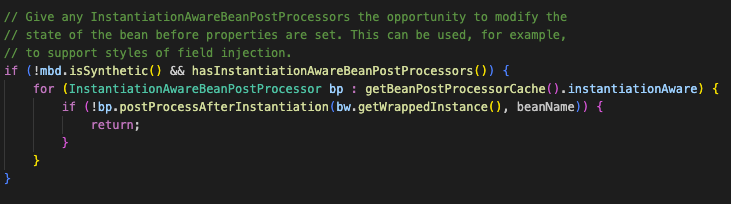
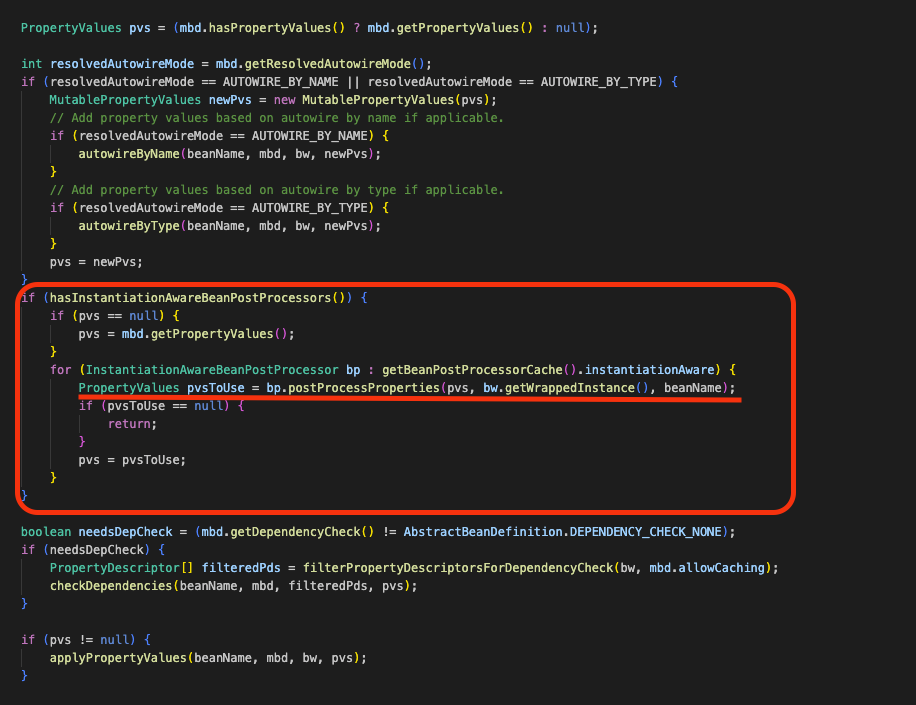
이어서 postProcessProperties()를 통해 실제 주입할 프로퍼티 값들을 가공합니다.
이 과정에서 AutowiredAnnotationBeanPostProcessor가 동작하며 @Autowired 필드/메서드 주입이 처리됩니다.
이후 마지막에 applyPropertyValues()가 호출되면서 앞에서 준비된 값들이 실제 Bean 인스턴스에 반영되는 것입니다.
다시 돌아가서, 지금까지의 흐름을 정리해보겠습니다.
ApplicationContext.refresh()가 호출되면 Spring 컨테이너는 먼저 refresh를 위한 사전 준비 작업을 수행합니다.
이후, BeanFactory를 새롭게 준비하고, BeanFactoryProcessor, BeanPostProcessor, 이벤트 멀티캐스터, 리스너 등록 등 컨테이너가 정상 동작하기 위한 기반을 갖추게 됩니다.
그 다음 finishBeanFactoryInitialization()단계에 도달하면, Spring은 남아 있는 non-lazy singleton Bean들을 실제로 생성하기 시작합니다. 이 과정은 preInstantiateSingletons()에서 이루어지며, Spring은 등록된 BeanDefinition이름 목록을 순회하며 추상 Bean이 아니고 singleton 범위인 Bean만 생성 대상으로 선별하게 됩니다.
그리고 각 Bean에 대해 preInstantiateSingleton (beanName, mbd)를 호출하고, 이 내부에서 다시 getBean(beanName) 흐름으로 내려가게 됩니다. 즉, 우리가 흔히 사용하는 Bean 생성과 DI의 실제 진입점은 결국 getBean()계열 메서드라고 볼 수 있습니다.
이후 doGetBean()에서는 먼저 singleton 캐시를 확인하고 필요하다면 부모 BeanFactory로 조회를 위임하거나 depends-on 관계를 먼저 해결합니다. 그리고 실제 생성이 필요하다고 판단되면 createBean()을 호출하며, 여기서부터 BeanDefinition이 실제 객체 인스턴스로 변환되는 단계로 들어가게 됩니다. createBean() 내부의 doCreateBean()에서는 먼저 cretaeBeanInstance()를 통해 객체 자체를 생성합니다. 이 단계에서는 생성자 주입, factory method, supplier, 기본 생성자 중 어떤 방식으로 객체를 만들 것인지를 결정하게 됩니다.
객체 생성이 끝나면 다시 doCreateBean()으로 돌아와 populateBean()을 통해 생성된 객체에 실제 의존성을 주입합니다.
이 과정에서 Spring은 곧바로 값을 넣지 않고 먼저 InstantiationAwareBeanPostProcessor에게 기회를 주고, 이후 postProcessProperties()를 통해 @Autowired와 같은 주입 메타 데이터를 해석합니다. 그리고 마지막으로 applyPropertyValues()를 통해 실제 값이 Bean 인스턴스에 반영됩니다.
즉, 지금까지 따라온 흐름을 다시 가볍게 정리하면, Spring의 DI는

- refresh()
- preInstantiateSingletons()
- getBean()
- doGetBean()
- createBeanInstance()
- populateBean()
의 순서로 진행되며, 객체 생성과 의존성 주입은 서로 분리된 단계로 진행된다는 것을 확인할 수 있습니다.
지금까지 Bean의 생성과정과 과정에서 Bean들의 의존성은 어떻게 주입받게 되는지까지를 살펴보았습니다.
그럼 이렇게 생성된 Bean은 어떻게 관리될까요?
8. 생성된 Bean의 관리
이제는 생성된 Bean을 컨테이너가 어떻게 보관하고 관리하는지도 함께 볼 필요가 있습니다.
Spring은 Bean을 단순히 한 번 만들고 끝내는 것이 아니라, 먼저 BeenDefinition 형태의 메타 정보를 이름 기반으로 등록해두고, 실제 생성이 끝난 Singleton Bean은 다시 별도의 Singleton 캐시에 저장해서 관리합니다. 즉, Spring 컨테이너는 Bean을 정의하는 저장소와 실제 singleton 객체의 저장소를 분리해서 운용한다고 볼 수 있습니다.
우선, Bean을 정의하는 저장소를 먼저 살펴보도록 하겠습니다.
DefaultListableBeanFactory 내부를 보면 아래와 같은 필드들이 선언되어 있습니다.

여기서 beanDefinitionMap은 말 그대로 BeanDefinition 자체를 보관하는 저장소입니다. key는 beanName, value는 BeanDefinition이며, Spring은 이 Map을 통해 '이 이름의 Bean은 어떤 클래스로 만들 것인가?', 'scope는 singleton인가?', 'lazy-init인가?', '생성자 인자는 무엇인가?'와 같은 메타 정보를 조회하게 됩니다.
즉, 아직 실제 객체를 저장하는 공간이 아니라 객체를 어떻게 만들어야 하는지에 대한 설계도 저장소라고 볼 수 있습니다.
반면, beanDefinitionNames는 등록된 Bean 이름들을 등록 순서대로 보관하는 리스트입니다.
앞에서 preInstantiateSingletons()를 따라가면서 보았던
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
코드도 바로 이 리스트를 복사해 순회하였던 것입니다. (앞에서 말했던 객체들을 그대로 안쓰고 복사해서 순회한다!!!는 설명 참고)
즉 Spring은 BeanDefinition을 Map으로만 관리하는 것이 아니라, 이름 목록도 별도로 유지하면서 순회,조회,초기화 순서 관리에 활용하고 있습니다.
정리하면, DefaultListableBeanFactory는 Bean을 한 군데에 저장하는 구조가 아니라
- beenDefinitionMap으로는 Bean 정의 자체를 이름 기반으로 관리하고
- beanDefinitionNames로는 등록된 Bean 이름 목록과 순서를 관리한는
구조인 것입니다. 그렇다면 이제 실제로 생성이 끝난 singleton Bean 객체는 어디에 저장될까요?
실제 생성된 singleton Bean 인스턴스는 별도의 singleton 캐시에서 관리됩니다.

빨간 밑줄로 확인해볼 수 있는 singletonObjects가 바로 실제 생성이 완료된 singletonBean 인스턴스를 담는 캐시입니다.
즉, Spring은 Bean을 관리할 때 생성 규칙은 BeanDefinition으로 따로 가지고 있고 실제 생성된 singleton 객체는 또 별도의 Map을 통한 캐시에 저장합니다. 그래서 getBean()이 호출되면 Spring은 먼저 BeanDefinition을 참고해 생성 전략을 판단하고, 이미 만들어진 singleton이 있다면 singletonObjects에서 꺼내 재사용하게 됩니다.
👀 마무리하며
여기까지 따라오셨다면, 이제 Spring에서 Bean이 어떤 과정을 거쳐 만들어지고, 그 이후 프레임워크 레벨에서 어떻게 관리되는지까지 전체 흐름을 어느 정도 코드 기준으로 이해하실 수 있을 것이라 생각합니다.
앞서 서론에서 던졌던 질문들을 다시 하나씩 정리해보겠습니다.
- Spring Container가 객체를 어떤 방식으로 관리하는지
→ Spring Container는 Bean을 단순히 하나의 자료구조에 모두 담아 관리하지 않습니다.
Bean을 어떻게 만들지에 대한 정보와 실제로 만들어진 객체를 어떻게 재사용할지를 분리해서 관리합니다.
우선, BeanDefinition은 Bean 생성 규칙을 담고 있는 메타정보입니다. 어떤 클래스를 Bean으로 만들 것인지,
scope는 무엇인지, lazy-init 여부는 어떤지, 생성자 인자는 무엇인지와 같은 정보들이 여기에 담깁니다.
Spring은 이러한 BeanDefinition을 ConcurrentHashMap 기반 저장소에서 관리하고, 등록된 Bean 이름 목록은
beanDefinitionNames라는 List로 별도로 관리합니다.
반면 실제 생성이 완료된 singleton Bean 인스턴스는 singletonObjects라는 별도의 ConcurrentHashMap 캐시에서
관리합니다. 따라서 Spring은 먼저 BeanDefinition을 참고해 생성 전략을 판단하고, 이미 생성된 singleton이 있다면
이를 다시 만들지 않고 singleton 캐시에서 꺼내 재사용합니다. - BeanDefinition, BeanFactory, ApplicationContext는 각각 어떤 역할을 하는지
→ BeanDefinition은 앞서 말한 것 처럼 하나의 설계도 역할을 합니다.
이 BeanName에 해당하는 객체를 어떤 방식으로 생성하고 초기화할지를 설명하는 메타 정보입니다.
BeanFacotry는 그 설계도를 바탕으로 실제로 Bean을 생성하고 조회하고 의존성을 붙이는 scope에 따라 객체를 관리하는
실질적인 생성 엔진입니다.
ApplicationContext는 그 위에서 더 큰 생명주기를 관리하는 상위 컨테이너입니다.
Bean을 생성하는 것을 넘어 refresh()를 통해 컨테이너 전체를 초기화하고 BeanFactoryPostProcessor,
BeanPostProcessor, 이벤트 시스템, 메시지 처리, 리스너 등록 등의 부가 기능까지 통합 관리합니다. - 의존성 주입은 실제로 어느 시점에 어떤 방식으로 수행되는지
→ 의존성 주입은 Bean이 등록되는 시점에 일어나는 것이 아니라, 실제 Bean 생성하는 과정 내부에서 수행됩니다.
createBeanInstance()를 통해 객체 자체를 생성한 뒤, 그 다음 populateBean()에서 실제 의존성 주입이 일어나게
되는 것입니다. - 그리고 이 모든 구조가 왜 Spring을 Spring 답게 만드는지
→ Spring은 BeanDefinition이라는 메타정보 기반 구조를 가지고 있고
BeanFactory를 통해 객체 생성과 조회를 일관되게 수행하며
ApplicationContext가 컨테이너 전체 생명주기를 통합 관리하고
BeanPostProcessor를 통해 생성 과정에 유연하게 개입할 수 있으며
의존성 해석, 초기화, Aware 콜백, 이벤트, 프록시 확장까지 하나의 컨테이너 안에서 처리됩니다.
즉, Spring은 객체 생성부터 주입, 초기화, 재사용, 확장 포인트 제공까지 전부 컨테이너 차원에서 체계적으로 관리하는
프레임워크입니다.
결국, 우리가 흔히 "Spring이 알아서 해준다"고 표현했던 한 문장 뒤에는 유기적으로 맞물린 정교한 내부 구조가 숨어있었던 것입니다. 또한, 객체 지향적인 프레임워크라는 말에 걸맞게 프레임워크 내부 코드들 역시 각자의 역할이 명확하게 분리되어 있고, 책임에 따라 계층적으로 구성되어 있음을 확인할 수 있었습니다.
평소에는 단순히 @Component, @Autowired, 생성자 주입 정도로만 체감되던 기능들이 실제로는 이처럼 정교하게 설계된 컨테이너 위에서 동작하고 있었던 것입니다. 코드를 보는데 JDK보다도 더 오랜 시간 (거의 2일 동안...)을 쓴 것 같지만, 그만큼 더 재미있었던 것 같습니다. 이번 Spring DI 흐름을 따라가보면서 Spring에서 사용하는 각각의 어노테이션들이 내부적으로 각각 어떤 방식으로 해석되고 동작하는지도 시간을 내서 직접 확인해보고 싶다는 생각이 들었습니다.
'Study' 카테고리의 다른 글
| (CS Study) Java Virtual Thread (feat. 모던 자바 동시성 프로그래밍) (0) | 2026.03.27 |
|---|---|
| (CS Study) Paging : OS Level 부터 Application Level까지 (0) | 2026.03.21 |
| (CS 스터디) 왜 Docker는 포트포워딩이 필요할까? - Linux Network Namespace부터 iptables까지 (0) | 2026.03.06 |
| (CS Study) Tomcat Internals : TCP Accept 부터 DispatcherServlet까지 (feat. Tomcat 소스코드로 추적하기) (0) | 2026.02.28 |
| (CS Study) 트랜잭션의 격리수준 어디까지 알고 계십니까? (0) | 2026.02.21 |
Contents
소중한 공감 감사합니다